- 行业先锋
- 文章详情

人工智能发展突飞猛进,各行各业均面临如何融合应用智能技术的关键之问,巨大应用潜力背后是新硬件、新算法、新数据的全面涌现。与此同时,ChatGPT被看作是推动数字经济时代生产力范式变革的标志性产品,有望作为新的底层通用技术,点燃第四次科技革命。一言以蔽之,人类社会正处在“跃迁”的关键时点。
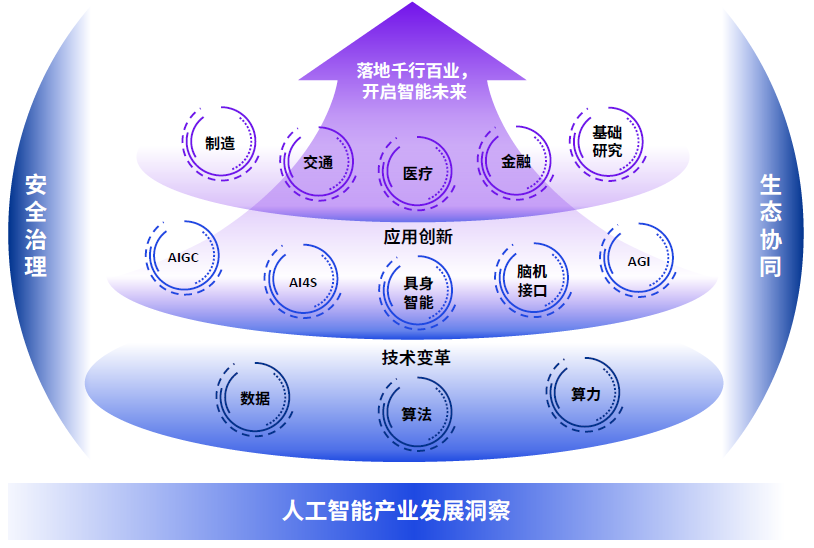
值此产业重大变革之机,毕马威联合中关村产业研究院通过行业调研和专家访谈,结合深入研究共同发布《人工智能全域变革图景展望:跃迁点来临(2023)》报告。该报告立足全球及中国的人工智能产业现状,结合市场观察从技术变革、应用创新、安全治理、生态协同四大维度,提出人工智能产业未来发展的十大趋势,并深度剖析各个趋势的发展情况与核心驱动力,以期能为AI产业界带来有益参考,锚定机遇,化解挑战(图1)。
图1:报告思路框架示意图
数据来源:毕马威分析,中关村产业研究院
全球人工智能产业愈发成熟冷静,中国作为领军之一有望把握范式变革机遇
各类AI企业层出不穷,AI细分标签日益庞杂,AI与各类前沿技术的融合创新更使得智能无处不在,在清晰界定AI产业范围和厘清AI企业的具体特点方面,产学研各界仍在探索。基于这一界定不清晰问题,本报告将人工智能产业链划分为基础层、技术层、应用层,并定义人工智能核心层为基础层和技术层。基础层包含数据、算力、算法“三驾马车”;技术层包含计算机视觉与模式识别、自然语言处理、类脑算法、语音技术、人机交互五类;应用层则包含所有AI技术与传统应用结合形成的产业种类。
从全球范围来看,人工智能企业数量经历了由爆发式增长转入稳步增长的阶段变化。从2017年开始,全球当年新增AI注册企业数量逐年下降,已从2017年的3,714家下降到2022年的1,106家。结合各国对比情况来看,截至2023年6月底,全球人工智能企业共计3.6万家,中美英企业数量名列前茅。美国人工智能企业数量约1.3万家,在全球占比达34%,中国占比16%,英国7%%,美中英三国的人工智能企业数量合计占全球的56%。从人工智能独角兽企业情况来看,截至2023年6月底,全球人工智能领域独角兽总数达291家,美国和中国企业数量独占鳌头并基本平分秋色,分别为131家和108家(图2)。
图2:全球人工智能独角兽企业按国家分布情况
》报告")
数据来源:毕马威分析,中关村产业研究院
中国人工智能领域企业密集诞生在2015年至2018年之间,约三分之二的人工智能领域核心企业成立年限在5-10年,随着有效投资增长乏力,人工智能领域新增注册企业数量在2017年达到峰值528家后,逐年下降,到2022年新增注册企业数减少至63家(图3)。
图3:2013年-2022年中国年度新增AI注册企业数量
》报告")
数据来源:毕马威分析,中关村产业研究院
结合区域布局来看,中国人工智能企业主要集聚于北京、广东、上海、浙江等地,形成京津冀、长三角、粤港澳三足鼎立的格局,其中北京市人工智能企业数量有1,600余家。从人工智能独角兽企业来看,北京市有41家,位居全国首位。上海市和广东省数量位列二、三,分别有24家和23家(图4)。
图4:全国人工智能独角兽企业分布情况
》报告")
数据来源:毕马威分析,中关村产业研究院
人工智能产业发展十大趋势
大模型爆发以来,人工智能技术发展日新月异,创新成果纷纷涌现,本报告从技术变革、应用创新、安全治理、生态协同四大维度总结出人工智能产业发展十大趋势,希望为有志于投身人工智能领域的企业和个人提供有益参考。
技术变革
ChatGPT引发的大模型创新热浪仍在涌动,有可能演变成一场比工业革命、信息革命更为深刻的人工智能革命。这一时代背景下,无论是推动大模型从单模态发展到多模态,还是倡导高质量数据和计算新范式,实际都在强调人工智能技术变革的本质——算法、数据、算力三大基础要素的精巧配合和相互促进。
趋势一:多模态预训练大模型将成为人工智能产业的标配
在算法方面,预训练大模型发展起源于自然语言处理(NLP)领域,当前已进入“百模大战”阶段,预计随着大模型创新从单模态转向多模态,多模态预训练大模型将逐渐成为人工智能产业的标配(图5)。目前,国内大模型虽在市场影响力方面稍逊色于GPT系列模型、PaLM-E等,但在中文语料训练、中国文化理解方面具备本土优势。此外,国内制造业等实体产业为大模型提供了丰富的训练数据和应用场景。未来,在大模型面向产业赋能方面,中国大模型极有可能后发先至,也会是国内大模型竞争的关键因素之一。
图5:大模型技术迭代历程
》报告")
数据来源:公开资料,毕马威分析,中关村产业研究院
目前,多模态预训练大模型发展思路主要有三:一是利用单模态模型如LLMs(大型语言模型)来调动其它数据类型的功能模块完成多模态任务,典型代表有Visual ChatGPT、Hugging GPT等;二是直接利用图像和文本信息训练得到多模态大模型,典型代表有KOSMOS-1等;三是将LLMs与跨模态编码器等有机结合,融合LLMs的推理检索能力和编码器的多模态信息整合能力,典型代表有Flamingo、BLIP2等。
趋势二:高质量数据愈发稀缺将倒逼数据智能飞跃
在数据方面,大模型的训练需要大量的高质量数据,但是目前在数据质量方面还存在一定的问题,包括数据噪声、数据缺失、数据不平衡等问题。这会影响大模型的训练效果和准确性。根据一项来自Epoch Al Research团队的研究,高质量的语言数据存量将在2026年耗尽,低质量的语言数据和图像数据的存量则分别在2030年至2050年、2030年至2060年枯竭。这意味着,如果没有新增数据源或是数据利用效率未能显著提升,那么2030年以后,AI大模型的发展速度将明显放缓。
预计大模型领域不断迸发的高质量数据需求,将倒逼数据在大规模、多模态、高质量三大维度上的全面提升,数据智能相关技术有望迎来跨越式发展。未来,基于云原生容器化环境,支持流、批数据处理的“湖仓一体”架构将成为新一代数据平台的底座,助力数据质量提升。此外,现代数据栈(Modern Data Stack)、数据编织(Data Fabric)等新型数据整理技术将极大提高数据处理效率,降低数据使用难度。机器学习、图计算等数据分析技术将有效拓展数据分析的维度和深度,有利于满足日益复杂的数据分析需求。自然语言处理等数据交互技术与向量数据库相结合,能够使计算机系统充分理解人类语言,在人机问答、知识检索等场景中,创造自然高效的用户体验。
趋势三:智能算力无处不在的计算新范式将加速实现
在算力方面,新硬件、新架构竞相涌现,现有芯片、操作系统、应用软件等都可能被推翻重来,预计有望实现“万物皆数据”“无数不计算”“无算不智能”,即智能算力将无处不在,呈现“多元异构、软硬件协同、绿色集约、云边端一体化”四大特征。
多元异构体现为CPU、GPU、ASIC、FPGA和NPU、DPU为代表的“XPU”芯片使得算力日趋多元化,传统x86架构之外,ARM、RISC-V、MIPS等多种架构也正在被越来越多的芯片公司所采纳,异构计算加速崛起。软硬件协同设计要求高效管理多类型资源,实现算力的弹性扩展、跨平台部署、多场景兼容等特性,例如,可以不断优化深度学习编译技术,提升算子库的性能、开放性和易用性,尽可能屏蔽底层处理器差异,向上兼容更多AI框架。绿色集约强调了对于数据中心和5G设施,平衡算力提升和能耗降低问题的重要性,包括提高绿色能源使用占比、采用创新型制冷技术降低数据中心能耗、综合管理IT设备提高算力利用效率等。云边端一体化则是在云端数据中心、边缘计算节点以及终端设备三级架构中合理部署算力,推动算力真正满足各类场景需求,边缘智能、AR/VR、自动驾驶等新一代计算终端渗透率有望大幅提升。
应用创新
全球人工智能角逐的制胜点除芯片、数据等核心领域外,场景应用创新也极其重要,一方面,场景应用中出现的短板和不足,能为技术突破提供切入点,另一方面,场景应用能否获得商业成功决定了产业化能否顺利推进。大模型技术将重塑生产消费的基本形态,以AIGC、AI4S、AGI为代表的应用场景中有望出现大量范式转换机会。
趋势四:人工智能生成内容应用向全场景渗透
在AIGC(Artificial Intelligence Generated Content,人工智能生成内容)应用方面,其发展源头在数字内容创作领域,从单模态内容到多模态数字化内容创建已初显雏形,预计未来会进一步提高人类创造内容的效率,丰富数字内容生态,开启人机协同创作时代,各种需要创意和新内容的场景,都可能被AIGC重新定义,AIGC向全场景渗透指日可待(图6)。
图6:AIGC应用落地时间表
》报告")
数据来源:红杉资本,毕马威分析,中关村产业研究院
具体到场景来看,AIGC目前集中在创造性工作场景中,包括广告营销、游戏创作、艺术设计等。一方面,创意属于稀缺资源,AIGC的创造性对激发灵感、辅助创作、验证创意等大有助益;另一方面,互联网大规模普及使得“一切皆可线上”,数字内容消费需求持续旺盛,AIGC能更低成本、更高效率地生产内容,经济性愈发凸显。不过,AIGC在内容准确性、细节把控度、风格个性化等方面仍有较大优化空间,AIGC潜力能否充分释放取决于和业务需求能否有效结合。
趋势五:人工智能驱动科学研究从单点突破加速迈向平台化
在AI4S(AI for Science,人工智能驱动的科学研究)应用方面,有望从单点突破加速迈向平台化,在“单点突破”阶段,AI4S发展由科研学者主导,数据、模型、算法及方法论的原创性是市场关注重点,AI4S在特定任务或场景中的“单点应用”初步证明了对应解决方案的落地价值。“平台化”发展则意味着,需要将这些已被证明的价值能力沉淀为平台化工具,提升对下游的通用性价值,与此同时,产业界对于AI4S的工程化需求也逐渐增加,工程师和科研学者将共同主导AI4S下一阶段的发展。
AI4S的平台化发展主要依靠四大工具的建设:模型算法和数据分析方法、高效率高精度的实验表征方法、数据库和知识库、专用芯片和高效整合的计算能力。落地路径主要为在共性平台和功能套件的基础上,针对特定学科的应用研究进行垂直整合,其他落地模式仍有待探索。目前亟需克服密集型计算数据庞杂无序、学科知识壁垒高、跨学科研究生态整合难度大等痛点。预计随着相关科研机构和科技企业不断沉淀底层数据分析和结构仿真设计能力,将更多“科学问题”转化为“计算和工程问题”,AI4S领域有望出现类似Transformer、GPT-3等的通用模型和框架,涌现一批“高效便捷、开箱即用”的科学研究智能化工具。
趋势六:具身智能、脑机接口等开启通用人工智能应用探索
在AGI(Artificial General Intelligence,通用人工智能)应用方面,其技术原理强调两大特性:一是需要基于先进算法实现智能处理和决策,包括深度学习、强化学习、进化计算等;二是需要具备和人类大脑相似的认知架构,包括感知、记忆、分析、思考、决策、创造等模块。参照AGI技术原理来看,ChatGPT在感知尤其是实时感知能力等方面,仍需进一步优化,而具身智能、脑机接口等技术的发展恰恰能带来有效助力。
但是,具身智能和脑机接口技术均处在早期技术孵化阶段,存在核心技术不成熟、研发成本较高、场景化应用难度高、监管制度缺位等突出问题,距离实现商业化应用还有较长一段距离。一些研究机构和企业已经开始探索具身智能、脑机接口如何与ChatGPT相结合,有望催生一批更符合AGI特征的应用。
安全治理
当前在人工智能领域无论是技术创新还是应用创新都堪称“万类霜天竞自由”,但自由是有限度的,日益复杂的算法规则和黑箱机制正在引发算法歧视、隐私泄露、虚假信息泛滥等科技伦理问题,加强安全治理刻不容缓,已经成为各方最大的共识。
趋势七:人工智能安全治理趋严、趋紧、趋难
人工智能安全治理呈现出趋严、趋紧、趋难三大特征,主要包括“黑箱”困境等技术安全挑战,虚假信息、偏见歧视乃至意识渗透等应用安全挑战,数据泄漏、篡改和真实性难验证等数据安全隐患,此背景下,中美欧三国作为人工智能发展的领军国和地区正积极开展相关立法,呈现出政策法规先行、监管趋严等特征(图7)。
欧洲已有专门的立法对人工智能进行强监管。2021年4月,欧盟委员会提出了《人工智能法案》提案,2023年6月14日法案在欧洲议会通过。按照立法程序,法案下一步将正式进入欧盟委员会、议会和成员国三方谈判协商,以确定法案的最终版本。届时该法案有望成为全世界第一部综合性人工智能治理立法,被各国监管机构广泛参考。与欧盟的法案属于正式立法不同,美国目前国家层面所颁布的框架和蓝图均为指导性文件,不具备法律效力。目前美国在人工智能领域的治理仍停留在行业自律为主、监管为辅的阶段。中国针对生成式人工智能的快速发展已颁布了两份具有法律约束效力的文件。此外,《国务院2023年度立法工作计划》显示,《人工智能法》已列入立法计划。从我国对人工智能领域的立法进程可以看出,我国在人工智能领域的安全治理主要体现出精准分层治理、创新与监管并进等治理理念和制度逻辑。
图7:部分国家针对人工智能治理颁布的典型法案
》报告")
数据来源:公开资料,毕马威分析,中关村产业研究院
趋势八:可解释AI、伦理安全、隐私保护等催生技术创新机遇
人工智能在发展过程中面临的技术伦理与社会伦理风险表明,人工智能安全、可信的发展之路任重道远,在解决AI风险的过程中催生出可解释AI、联邦学习等技术创新机遇。其中,联邦学习正成为新型的“技术基础设施”,有望成为下一代人工智能协同算法,隐私计算和协作网络的基础,使数据在合法合规、安全高效的基础上,实现数据价值流动。
此外,通过“为机器立心”,逐步实现人机价值观对齐,即要求AI系统的目标要和人类的价值观与利益相对齐或保持一致也是AI伦理价值的重要发展方向。AI对齐是走向通用人机协作的第一步,未来AI对齐的研究方向不仅仅局限于单任务环境,将进一步探索多个任务中的人机价值对齐。此外,信念、欲望、意图等人机之间心理模型的因素是“为机器立心”的过程,也是重要研究方向。
生态协同
人工智能产业生态协同主要体现在三方面,一是人工智能技术自身进步带来的数据、算力、算法协同,二是人工智能与传统产业等实体经济的协同;三是人工智能领域各参与主体之间相互协同。以开源创新为基石,以MaaS这一崭新商业模式为核心,有望带动人工智能产业生态繁荣发展,最终实现人工智能高质量发展。
趋势九:开源创新将是AGI生态建设的基石
AGI强调人工智能的通用性,意味着其生态需满足大量细分场景和长尾需求,这种情况下,生态系统越是繁荣开放,越能穷尽可能地覆盖所有专用化、场景化乃至碎片化的需求,保证AGI生态的丰富性和完整性。进一步地,开发者越多,意味着底层模型和上层应用等的迭代速度也会越快。但是,开源也存在一定风险,对于产业生态中的主体企业来说,选择开源某种程度上就意味着公开商业机密,不利于其构建竞争壁垒。此外,开源模式还可能会引发专利侵权风险,对开源的知识产权管理规则和流程规范建立提出了挑战。
中国长期强调构建开源创新体系,预计随着鼓励人工智能技术创新生态和开源社区的相关政策不断出台,企业等主体积极参与建设,开源创新有望成为中国AGI生态的重要基石之一,推动中国在前沿理论创新方面取得重大突破,从“跟跑”走向“领跑”。
趋势十:模型即服务(MaaS)将是AGI生态构建的核心
商业模式关乎整体生态能否实现从价值创造到价值实现的完整闭环,目前AGI生态的商业模式主要以AIGC相关的商业模式为代表,主要体现为MaaS(Model as a Service,模型即服务)模式。该模式核心价值可归纳为:降低算法需求侧的开发技术和使用成本门槛,使AI模型和应用成为简单易用、触手可得的工具。由此,需求侧用户可以专注自身业务逻辑和使用体验,而不必关注底层技术细节,有利于解决AI“能用”但“不好用”的这一关键落地瓶颈。而在供给侧,有望形成“通用大模型+领域大模型+行业大模型+企业/个人小模型”这一基础业态(图8),推动AI落地千行百业,最终实现AGI。
图8:MaaS模式下的AGI基础业态分析
》报告")
数据来源:阿里云栖大会,毕马威分析,中关村产业研究院
在AGI基础业态中,通用大模型和领域专用模型处于基础层,发挥着基础设施的作用,具有通用性强、多模态乃至跨模态的特点,技术难度高且成本投入巨大,拥有高质量数据、强大的多元异构计算能力、自研大模型的科技巨头企业将是主要参与者;行业大模型在中间层,相较基础层来说更为直接地深入到特定行业,在模型训练方面会接入较稀缺的行业Know-how数据,在部署方面会更多采用API接口、SDK私部署的形式,呈现出工具化、平台化趋势。企业和个人小模型处在应用层,在大模型基础上蒸馏、裁剪后再使用,具有高性价比、部署高效、安全可靠等特点,小模型功能会以插件形式与SaaS应用、智能硬件等相结合,成为AGI时代的流量入口。
文章来自于微信公众号 “毕马威KPMG”,作者 “毕马威KPMG”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则