- 行业先锋
- 文章详情

昨天,号称当前最强、最高效的长上下文模型——Jamba 1.5 系列发布。
Jamba 是第一个基于 Mamba 架构的生产级模型。Mamba 是由卡内基梅隆大学和普林斯顿大学的研究人员提出的新架构,被视为 Transformer 架构的有力挑战者。
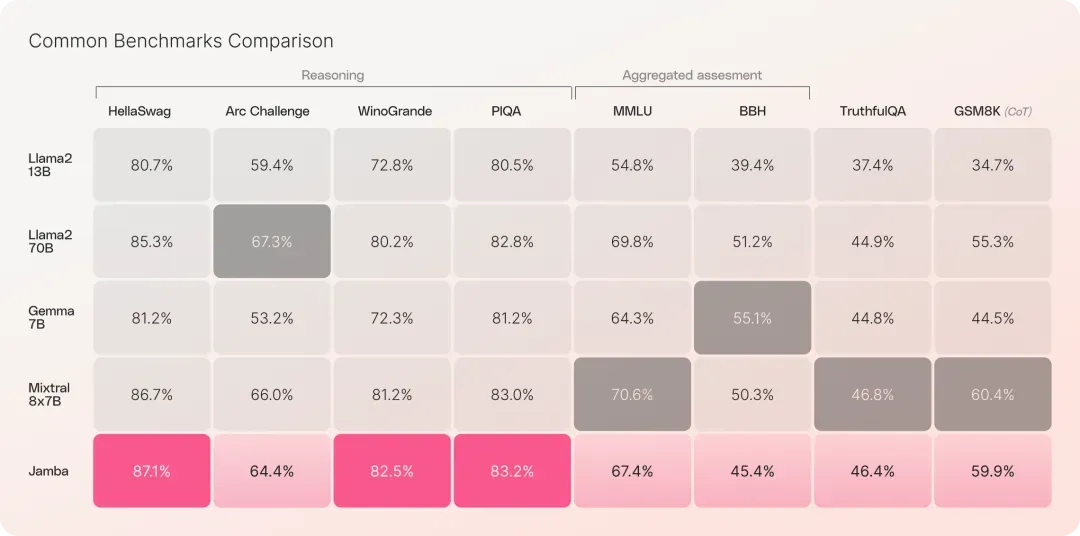
基于评估,Jamba 1.5 拥有最长的有效上下文窗口,在同等大小的所有上下文长度中速度最快,质量得分超过 Llama 3.1 70B 和 405B。
AI21 Labs 是谁?
AI21 Labs 由人工智能先驱 Amnon Shashua 教授(Mobileye 创始人兼首席执行官)、Yoav Shoham 教授(斯坦福大学名誉教授、前谷歌首席科学家)和 Ori Goshen(CrowdX 创始人)于 2017 年创立,目标是打造成为人类思想伙伴的人工智能系统。
2023 年 8 月,AI21 Labs 宣布完成 1.55 亿美元的 C 轮融资,投资者包括 Walden Catalyst、Pitango、SCB10X、b2venture、Samsung Next 和 Amnon Shashua 教授,Google 和 NVIDIA 也参与其中。
新一轮融资使该公司的融资总额达到 2.83 亿美元,估值达 14 亿美元。
2023 年 11 月 22 日,AI21 Labs 又宣布 C 轮融资完成 2.08 亿美元的超额认购,总融资额从 2.83 亿美元增至 3.36 亿美元。这一轮的投资方包括英特尔资本、康卡斯特风险投资公司、Ahren Innovation Capital 等。
从投资者可以看出,AI21 Labs 主要吸引的是产业资本。这也符合 AI21 Labs 的市场定位,就是面向特定企业客户开发定制模型,帮助企业设计自己的生成式 AI 应用程序。
AI21 联合首席执行官兼联合创始人 Ori Goshen 表示:「一刀切的政策并不适合所有人,因为企业正在寻找能够理解其特定需求的独特合作伙伴。大规模部署人工智能需要深入了解能够提供更好价值和影响的高性能语言模型。我们的方法是有目的地设计人工智能,使其比从头开始构建效率更高,而且更具成本效益。」
Jamba 1.0:第一个基于 Mamba 的生产级模型
2024 年 3 月 28 日,AI21 Labs 宣布推出 Jamba,这是世界上第一个基于 Mamba 的生产级模型。
通过利用传统 Transformer 架构的元素增强 Mamba 结构化状态空间模型 (SSM) 技术,Jamba 弥补了纯 SSM 模型的固有局限性。它提供 256K 上下文窗口,已经展示了吞吐量和效率的显著提升——这只是这种创新混合架构所能实现的开始。值得注意的是,Jamba 在各种基准测试中都优于或匹敌同规模的其他最先进模型。
主要特点:
- 第一个基于新颖的 SSM-Transformer 混合架构构建的生产级 Mamba 模型
- 与 Mixtral 8x7B 相比,长上下文的吞吐量提高了 3 倍
- 民主化访问大规模 256K 上下文窗口
- 同类模型中唯一一款能够在单个 GPU 上容纳高达 140K 上下文的模型
- 在 Apache 2.0 下以开放权重发布
- 已在 Hugging Face 上提供,即将在 NVIDIA API 目录中推出
Jamba 的发布标志着 LLM 创新的两个重要里程碑:成功地将 Mamba 与 Transformer 架构结合起来,并将混合 SSM-Transformer 模型推进到生产级的规模和质量。
到目前为止,LLM 主要建立在传统的 Transformer 架构上。虽然这种架构无疑非常强大,但它存在两个主要缺点:
- 内存占用大:Transformer 的内存占用随上下文长度而变化。这使得在没有大量硬件资源的情况下运行长上下文窗口或大量并行批次变得具有挑战性,从而限制了广泛的实验和部署机会
- 随着上下文的增长,推理速度变慢:Transformer 的注意力机制随着序列长度呈二次方增长,并降低了吞吐量,因为每个 token 都依赖于它之前的整个序列——将长上下文用例置于高效生产的范围之外
Mamba 由卡内基梅隆大学和普林斯顿大学的研究人员提出,它解决了这些缺点,为语言模型开发开辟了新的可能性。然而,由于不关注整个上下文,这种架构很难达到现有最佳模型的输出质量,尤其是在与回忆相关的任务上。
为了充分利用 Mamba 和 Transformer 架构的优势,AI21 Labs 开发了相应的联合注意力和 Mamba (Jamba) 架构。Jamba 由 Transformer、Mamba 和混合专家 (MoE) 层组成,可同时优化内存、吞吐量和性能。

Jamba 的 MoE 层允许它在推理时仅利用其可用的 52B 参数中的 12B,并且其混合结构使得这 12B 活动参数比同等大小的仅 Transformer 模型更高效。
虽然有些人尝试过扩展 Mamba,但没有人将其扩展到 3B 参数之外。Jamba 是同类中第一个达到生产级规模的混合架构。
要成功扩展 Jamba 的混合结构,需要进行几项核心架构创新。
如下图所示,AI21 的 Jamba 架构采用块层方法,使 Jamba 能够成功整合两种架构。每个 Jamba 块包含一个注意力层或一个 Mamba 层,后面跟着一个多层感知器 (MLP),总比例为每八层中有一个 Transformer 层。

第二个特点是利用 MoE 来增加模型参数的总数,同时精简推理时使用的活动参数数量,从而提高模型容量,而无需相应增加计算要求。为了在单个 80GB GPU 上最大限度地提高模型的质量和吞吐量,我们优化了使用的 MoE 层和专家的数量,为常见的推理工作负载留出了足够的内存。
根据初步评估,Jamba 在吞吐量和效率等关键指标方面表现出色。
在长上下文中提供 3 倍的吞吐量,使其成为比 Mixtral 8x7B 等同等大小的基于 Transformer 的模型更高效的模型。

Jamba 可以在单个 GPU 上容纳 140K 上下文,与目前其他类似规模的开源模型相比,它为部署和实验提供了更多的机会。

Jamba 1.5:最强大、最高效的长上下文模型
昨天,AI21 Labs 推出模型更新——Jamba 1.5 系列开放模型:Jamba 1.5 Mini 和 Jamba 1.5 Large。
这些模型基于新颖的 SSM-Transformer 架构构建,具有出色的长上下文处理能力、速度和质量——超越了同尺寸级别的竞争对手,并标志着非 Transformer 模型首次成功扩展到市场领先模型的质量和强度。
市面上的通用模型很强大,比如 GPT-4o,但往往与企业的落地之间有一个的 gap。AI21 Labs 通过为企业定制模型来解决,这些模型更加考虑到大型企业最关心的关键指标:资源效率、质量、速度和实际解决关键任务的能力:
- 长上下文处理:Jamba 1.5 型号拥有市场上最长的 256K 有效上下文窗口,可以提高关键企业应用程序的质量,例如长文档摘要和分析,以及代理和 RAG 工作流程
- 速度:在长上下文中速度最高可提高 2.5 倍,在同等大小的所有上下文长度中速度最快
- 质量:Jamba 1.5 Mini 是同尺寸级别中最坚固的开放式型号,在 Arena Hard 基准测试中得分为 46.1,超过 Mixtral 8x22B 和 Command-R+ 等大型型号。Jamba 1.5 Large 得分为 65.4,超过 Llama 3.1 70B 和 405B
- 多语言:除英语外,该型号还支持西班牙语、法语、葡萄牙语、意大利语、荷兰语、德语、阿拉伯语和希伯来语
- 开发人员就绪:Jamba 原生支持结构化 JSON 输出、函数调用、摘要文档对象和生成引文
- 向建设者开放:两种模型均可在 Hugging Face 上立即下载(并且即将在领先框架 LangChain 和 LlamaIndex 上推出)
- 随处部署:除 AI21 Studio 外,这些模型还可在云合作伙伴 Google Cloud Vertex AI、Microsoft Azure 和 NVIDIA NIM 上使用,并且即将在 Amazon Bedrock、Databricks Marketplace、Snowflake Cortex、Together.AI 以及私有本地和 VPC 部署上使用
资源高效的混合架构
Jamba 1.5 Large 和 Mini 采用新颖的 SSM-Transformer Jamba 架构,将 Transformer 的卓越品质与 Mamba 的突破性效率融为一体。
因此,这些模型的内存占用比竞争对手更低,允许客户使用 Jamba 1.5 Mini 在单个 GPU 上处理长达 140K 个 token 的上下文。与基于 Transformer 的模型相比,同样的优势还使得对长上下文的微调更容易、更方便。得益于这种效率优化的架构,我们的模型可以提供顶级质量和速度,而无需大幅增加成本。
与其大小类别中的所有模型一样,Jamba 1.5 Large 无法在 8 个 GPU 的单个节点上以全精度 (FP32) 或半精度 (FP16/BF16) 加载。由于对当前可用的量化技术不满意,AI21 开发了 ExpertsInt8,这是一种专为 MoE 模型量身定制的新型量化技术。
使用 ExpertsInt8,仅量化属于 MoE(或 MLP)层的权重,对于许多 MoE 模型而言,这些权重占模型权重的 85% 以上。在 AI21 的实现中,将这些权重量化并以 8 位精度格式 INT8 保存,并在运行时直接在 MoE GPU 内核中对其进行反量化。
该技术有四个优点:速度快,量化只需几分钟;它不依赖于校准,校准有时是一个不稳定的过程,通常需要几个小时或几天;它仍然可以使用 BF16 来保存大型激活;而且重要的是,它允许 Jamba 1.5 Large 安装在单个 8 GPU 节点上,同时利用其 256K 的完整上下文长度。在实验中,ExpertsInt8 被证明是所有 vLLM 量化技术中 MoE 模型延迟最低的,而且质量没有损失。
真正传递信息的长篇背景
Jamba 1.5 模型提供的 256K 上下文窗口不仅是开放模型中最长的,而且也是唯一在 RULER 基准测试中支持这一说法的模型。

虽然大多数其他型号都声称具有长上下文窗口,但无法在其上下文窗口的上限维持相同的性能质量,但 Jamba 1.5 系列在其 256K 上下文窗口的整个跨度内都保持其长上下文处理。
对于几乎所有企业级 GenAI 应用来说,能够有效处理长上下文的模型都至关重要。除了彻底而准确地总结和分析长文档之外,长上下文模型还可以显著提高 RAG 和代理工作流的质量,并降低其成本,因为无需进行连续分块和重复检索。
虽然有时人们声称 RAG 是长上下文的替代品,但成功的企业 AI 系统需要两者。通过将长上下文与 RAG 配对,长上下文模型可以提高 RAG 大规模检索阶段的质量和成本效益。
市场上最快的
对于企业感兴趣的用例,例如客户支持代理助理和聊天机器人,快速周转至关重要。即使使用请求和批次大小增加,模型也需要能够跟上运营规模。
两种 Jamba 1.5 型号都比同等规模的竞争对手速度更快,在长上下文中的推理速度最高可提高 2.5 倍,在客户自己的环境中部署时,可在高利用率下为客户带来成本、质量和速度方面的显著提升。

Jamba 1.5 Mini 比较是在 2xA100 80GB GPU 上进行的,而 Jamba 1.5 Large 比较是在 8xA100 80GB GPU 上进行的。测试是在 vLLM 上进行的,batch_size=1、output_tokens=512、input_tokens=(context_length-512)
Jamba 1.5 Mini 和 Jamba 1.5 Large 在 Artificial Analysis 运行的测试中表现出了出色的速度和吞吐量结果,如下图所示,Jamba 1.5 Mini 在 10K 环境中排名最快。

经 Artificial Analysis 独立测试,在 10K 上下文中每秒输出标记数。
全面卓越的品质
根据 Arena Hard 基准测试,Jamba 1.5 Mini 成为同尺寸级别中最强大的型号,超越了竞争对手 Claude 3 Haiku、Mixtral 8x22B 和 Command-R+。Jamba 1.5 Large 同样超越了 Claude 3 Opus、Llama 3.1 70B 和 Llama 3.1 405B 等领先型号,在同尺寸级别中具有出色的性价比。


文章来自微信公众号 “ Founder Park “

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则