- 行业先锋
- 文章详情

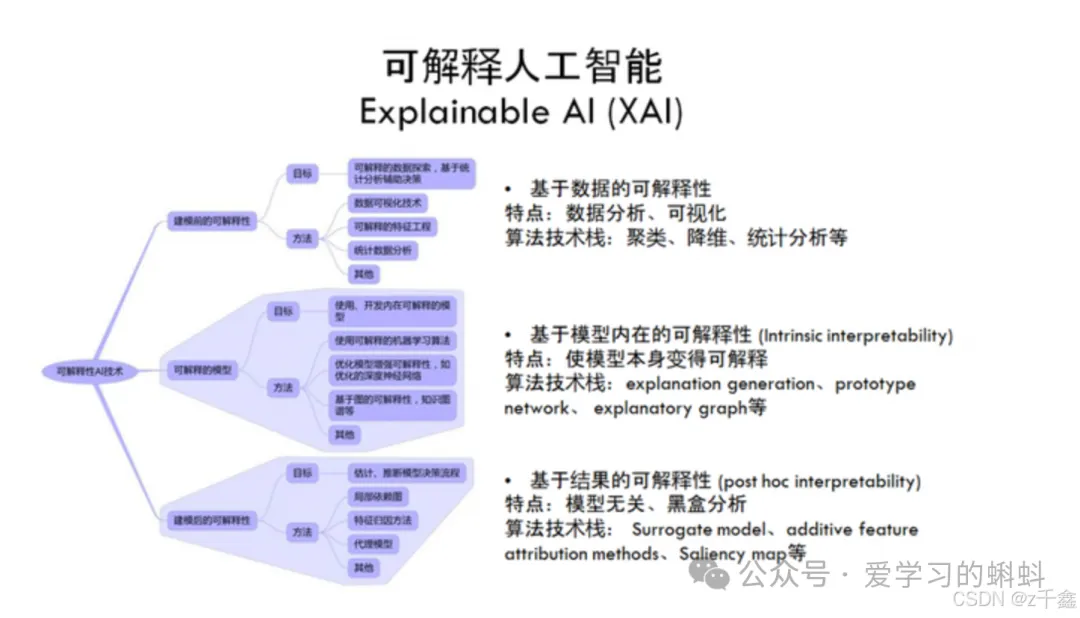
在当今人工智能(AI)和机器学习(ML)技术迅猛发展的背景下,解释性AI(Explainable AI, XAI)已成为一个备受关注的话题。随着AI在医疗、金融、自动驾驶等高风险领域的广泛应用,理解模型的决策过程显得尤为重要。XAI的核心目标是为复杂的机器学习模型提供人类可理解的解释,帮助用户深入了解模型如何做出决策,从而提升模型的透明度和可信度。 @
- 解释性AI是什么?
- 解释性AI的常见方法
- 1. SHAP(Shapley Additive Explanations)
- 2. LIME(Local Interpretable Model-agnostic Explanations)
- 示例代码:使用SHAP解释随机森林模型
- 示例代码:使用LIME解释随机森林分类器
- 解释性AI的优势
- 结语
解释性AI是什么?
解释性AI是一系列方法和技术,旨在帮助人们理解AI模型的输出是如何生成的。通过引入解释性层,AI系统不仅能够提供预测结果,还能解释这些预测背后的逻辑。XAI的应用有助于提高模型的透明度,确保AI决策的公正性和可靠性,尤其在涉及人类生命和财产安全的领域。
解释性AI的核心价值
1.透明度 透明度是解释性AI的核心价值之一。XAI通过提供详细的解释,确保用户能够理解模型的决策过程。这种透明度不仅有助于用户识别模型的优缺点,还能揭示模型在特定情况下的行为模式。通过清晰的解释,用户能够更好地把握模型的局限性,从而在实际应用中做出更为合理的判断。
2.公平性 解释性AI在确保AI决策的公平性方面发挥着重要作用。通过分析模型的决策过程,XAI能够识别和纠正模型中的潜在偏差,避免不必要的歧视和误判。例如,在招聘系统中,XAI可以帮助识别是否存在性别或种族偏见,从而确保招聘过程的公正性。这种公平性不仅提升了用户的满意度,也增强了社会对AI技术的信任。
3.信任 信任是AI系统成功应用的关键因素之一。通过清晰的解释,XAI增强了用户对AI系统的信任,使其在高风险环境中更具适用性。尤其是在医疗和金融等领域,用户往往需要对AI系统的决策有充分的信任,以便在关键时刻依赖这些系统做出决策。信任的建立不仅依赖于模型的准确性,还依赖于模型的可解释性。用户越能理解模型的决策过程,越容易信任其输出。
4.可持续性 随着AI技术的不断发展,解释性AI还为模型的可持续性提供了保障。通过对模型进行解释,开发者能够更好地识别模型的不足之处,从而进行优化和改进。这种持续的反馈机制不仅提升了模型的性能,也为未来的AI应用奠定了基础。
【主流大模型集聚地:GPT-4o-Mini、GPT-3.5 Turbo、GPT-4 Turbo、GPT-4o、GPT-o1、Claude-3.5-Sonnet、Gemini Pro、月之暗面、文心一言 4.0、通易千问 Plus等众多模型】????传送门:https://www.nyai.chat/chat?invite=nyai_1141439&fromChannel=hp_gzh
解释性AI的常见方法
在解释性AI(XAI)领域,SHAP和LIME是两种最为常用且有效的技术,它们各自具有独特的优势和应用场景。以下是对这两种方法的更详细描述:
1. SHAP(Shapley Additive Explanations)
SHAP是一种基于博弈论的模型不可知方法,旨在量化每个特征对模型预测结果的贡献。其核心思想源自于博弈论中的Shapley值,旨在公平地分配每个参与者(特征)在合作游戏(模型预测)中的贡献。
主要特点:
- 全局与局部解释:SHAP不仅能够提供全局解释,揭示特征在整个数据集中的重要性,还能针对单个实例进行局部解释,帮助用户理解特定预测的原因。
- 一致性:SHAP的一个重要优势是它能够为各种模型生成一致的解释。这意味着无论使用的是线性回归、决策树还是深度学习模型,SHAP都能提供相同的解释框架,使得不同模型之间的比较变得更加简单和直观。
- 可视化工具:SHAP提供了多种可视化工具,如SHAP值图、特征重要性图等,帮助用户直观理解特征对模型预测的影响。这些可视化工具使得复杂的模型决策过程变得更加透明。
- 模型不可知性:SHAP是一种模型不可知的方法,意味着它可以应用于任何类型的机器学习模型,而无需对模型的内部结构有深入了解。这种灵活性使得SHAP在实际应用中非常受欢迎。
——揭开机器学习模型的“黑箱”")
2. LIME(Local Interpretable Model-agnostic Explanations)
LIME是一种局部可解释模型不可知方法,旨在通过构建一个简单的解释性模型来解释复杂模型的输出。LIME的核心思想是通过对输入数据进行扰动,观察模型预测的变化,从而推断出特征对预测结果的影响。
主要特点:
- 局部模型生成:LIME通过在特定实例周围生成一个局部的简单模型(如线性模型),来近似复杂模型的行为。这种方法使得用户能够理解在特定输入条件下,模型是如何做出决策的。
- 灵活性:LIME适用于多种机器学习模型,包括深度学习、集成学习等。其灵活性使得它能够在不同的应用场景中发挥作用,尤其是在需要解释复杂模型的情况下。
- 特征扰动:LIME通过对输入特征进行随机扰动,生成多个新的数据点,并观察模型的预测变化。这种方法能够揭示特征对模型输出的敏感性,从而帮助用户理解模型的决策过程。
- 可解释性与准确性平衡:LIME在提供可解释性的同时,尽量保持对复杂模型的准确性。通过局部模型的构建,LIME能够在一定程度上保留复杂模型的预测能力,同时提供易于理解的解释。
——揭开机器学习模型的“黑箱”")
在这里插入图片描述
示例代码:使用SHAP解释随机森林模型
以下代码展示了如何使用SHAP解释一个随机森林回归模型的预测结果。我们将使用经典的波士顿房价数据集作为示例。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import shap
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_openml
# 加载波士顿房价数据集(使用fetch_openml以替代load_boston)
boston = fetch_openml(name='boston', version=1, as_frame=True)
X = boston.data
y = boston.target
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林回归模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 评估模型性能
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.2f}')
# 创建SHAP解释器
explainer = shap.TreeExplainer(model)
# 计算SHAP值
shap_values = explainer.shap_values(X_test)
# 可视化SHAP值
shap.summary_plot(shap_values, X_test, plot_type="bar")
在上述代码中,shap.summary_plot()会生成一个特征重要性图,显示哪些特征对模型的预测影响最大。例如,“LSTAT”(低收入人口比例)和“RM”(每栋房屋的平均房间数)可能是影响房价的重要因素。
示例代码:使用LIME解释随机森林分类器
接下来,我们将使用LIME解释随机森林分类器在鸢尾花数据集上的预测结果。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from lime.lime_tabular import LimeTabularExplainer
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def load_data():
"""加载鸢尾花数据集"""
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
return X, y
def train_model(X_train, y_train):
"""训练随机森林分类器"""
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
return model
def evaluate_model(model, X_test, y_test):
"""评估模型性能"""
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
def explain_instance(explainer, instance, model):
"""解释单个实例的预测"""
exp = explainer.explain_instance(instance, model.predict_proba)
return exp
def main():
# 加载和分割数据集
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = train_model(X_train, y_train)
# 评估模型性能
evaluate_model(model, X_test, y_test)
# 创建LIME解释器
explainer = LimeTabularExplainer(X_train.values,
feature_names=X.columns.tolist(),
class_names=load_iris().target_names,
mode='classification')
# 选择测试集中的第一个实例进行解释
instance_index = 0
exp = explain_instance(explainer, X_test.iloc[instance_index].values, model)
# 打印和可视化解释结果
print(exp.as_list())
exp.show_in_notebook(show_table=True)
if __name__ == "__main__":
main()
该代码展示了如何使用LIME解释模型的局部决策,通过扰动输入特征,LIME生成了对单个预测的解释。
解释性AI的优势
- 透明度:XAI通过提供详细的解释,确保用户能理解模型的决策过程,进而增强对AI系统的信任。
- 公平性:解释性AI有助于识别和纠正模型中的潜在偏差,确保AI决策的公平性,避免不必要的歧视和误判。
- 信任:通过清晰的解释,XAI增强了用户对AI系统的信任,使其在高风险环境中更具适用性。
????codemoss_能用AI
【无限GPT4.omini】 【拒绝爬梯】 【上百种AI工作流落地场景】 【主流大模型集聚地:GPT-4o-Mini、GPT-3.5 Turbo、GPT-4 Turbo、GPT-4o、GPT-o1、Claude-3.5-Sonnet、Gemini Pro、月之暗面、文心一言 4.0、通易千问 Plus等众多模型】
????传送门:https://www.nyai.chat/chat?invite=nyai_1141439&fromChannel=hp_gzh
——揭开机器学习模型的“黑箱”")
在这里插入图片描述
结语
随着AI的应用越来越广泛,解释性AI正成为构建透明和可信模型的关键工具。无论是SHAP还是LIME,它们都为复杂模型提供了深入的可解释性,帮助开发者和用户更好地理解AI系统的行为,确保其在实际应用中更加可靠和公平。
如果您对解释性AI有更多的兴趣,欢迎关注我的CSDN博客,获取更多关于AI和机器学习的深度分析与实用教程!????
文章来自于微信公众号“爱学习的蝌蚪”,作者“hpstream”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则