- 行业先锋
- 文章详情

零一万物的最新模型,打榜赢了GPT-4o。
“零一万物绝不放弃预训练。”
2024年10月16日,AI独角兽零一万物创始人兼CEO李开复,公开立了军令状。也在同一天,零一万物发布了最新的MoE(混合专家)架构的旗舰大模型:Yi-Lightning。
这也是时隔5个月后,零一万物再次更新模型的新动态。
李开复表示,Yi-Lightning的训练只用了2000张GPU,训练周期仅一个半月,成本只有300多万美元,是埃隆·马斯克的xAI成本的1%、2%。
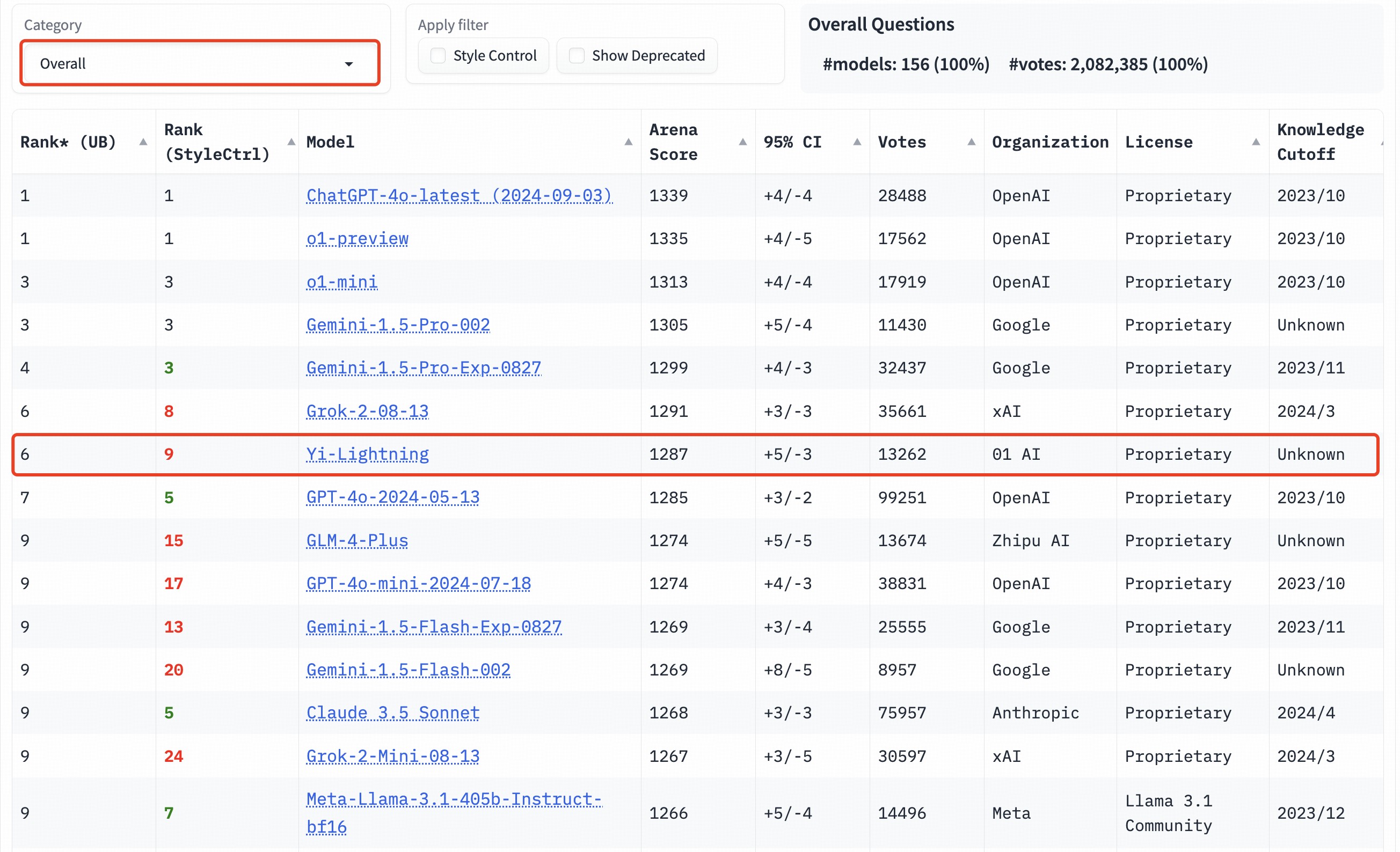
训练成本虽然低,但Yi-Lightning的性能并没有打折扣。在加州大学伯克利分校LMSYS团队的Chatbot Arena(聊天机器人竞技场)总榜单上,Yi-Lightning的性能与xAI的Grok-2-08-13模型并列第6,并且超越了OpenAI的GPT-4o-2024-05-13。
LMSYS团队的Chatbot Arena(聊天机器人竞技场)大语言模型综合能力总榜单。图源:零一万物
值得注意的是,在中文能力上,Yi-Lightning与OpenAI的最新模型o1-mini版本并列取得了第二;在数学能力上,Yi-Lightning和Gemini-1.5-Pro-002并列第3,仅次于在数学、逻辑推理见长的o1。
在定价上,Yi-Lightning也创了零一万物模型的最低定价:0.99元/百万Token。

零一万物模型定价。图源:零一万物官网
当然,榜单排名并不意味着模型在任务场景下的能力。在发布会上,零一万物着重在实用性上,让Yi-Lightining秀了一把肌肉。
比如,Yi-Lightining相比2024年5月发布的Yi-Large,首包时间(从接收到任务请求到系统开始输出响应结果之间的时间)缩短了一半,最高生成速度提升了近四倍。
具体到翻译场景,Yi-Lightining比豆包、DeepSeek、通义千问最新旗舰模型的翻译速度更快,且翻译结果更加信达雅。

四个模型在相同翻译任务上的表现。图源:零一万物
发布会上,李开复也揭秘了Yi-Lightning的训练策略:
- 独特的混合注意力机制(Hybrid Attention):在处理长序列数据的过程中,能够提高性能的同时,还能降低推理成本;
- 动态Top-P路由机制:根据任务难度自动选择最合适的专家网络组合;
- 多阶段训练(Multi-stage Training):让模型在不同阶段吸收不同的知识,方便mixing团队进行数据配比的调试工作,并能保证不同阶段的训练速度和稳定性。
在2024年5月份的发布会上,零一万物在国内发布了C端的生产力产品“万知”。时隔五个月,零一万物的B端商业化版图也有了新的进展——聚焦零售和电商等场景的AI 2.0数字人。
AI 2.0数字人的背后,是电商话术大模型、角色大模型、直播声音大模型的多模态协同训练。目前,AI 2.0数字人还接入了Yi-Lightning。用户只需要输入出售的商品、声音的性别和语调,就能生成相应的数字人。

零一万物AI 2.0数字人接入Yi-Lightning前后对比。图源:零一万物
如今,大模型发展也来到了技术探索的深水区。即便立下了“绝不放弃预训练”的军令状,李开复也承认:“但不是每家公司都可以做这件事情,做这件事情的成本也比较高,以后有可能会越来越少的大模型公司训练做预训练。”
不过,对如今六家大模型独角兽,李开复依然抱有乐观的态度:
“据我所知,这六家公司融资额度都是够的,我们做预训练的production run,训练一次三四百万美金,这个钱也是头部公司都付得起,我觉得中国的六家大模型公司只要有够好的人才,想做预训练的决心,融资额跟芯片都不会是问题的。”
文章来自于“ 36氪”,作者“ 周鑫雨”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则