- 行业先锋
- 文章详情

全网 OpenAI o1 的测试基本跑完,大家基本认可这是一个独立思考智商超高的模型,智商测试120,高考数学全对。
但是当人们询问模型的思维过程时,却收到 OpenAI 的封号警告,这有什么不能问的?
o1 的思维过程里到底隐藏着怎样的秘密,才会受到如此严密的保护?
带着这个疑问看完了模型的技术报告,似乎有点懂了…
一、先从光鲜亮丽的那一面说起
OpenAI 发布新模型系列 OpenAI o1,新模型的非常特殊,各种能力缺失:不支持联网搜索、不支持文件、不支持画图,也不支持 system prompt,不支持 tool,不支持 json mode,不支持结构化输出。
尽管缺少了所有这些技术工程,新模型只能独立思考,但其价格依然是旧模型的100倍,原因就是:
新模型会进行系统2思考,通过花费更多时间思考,能够推理复杂任务,并解决科学、编程、数学领域中的难题。
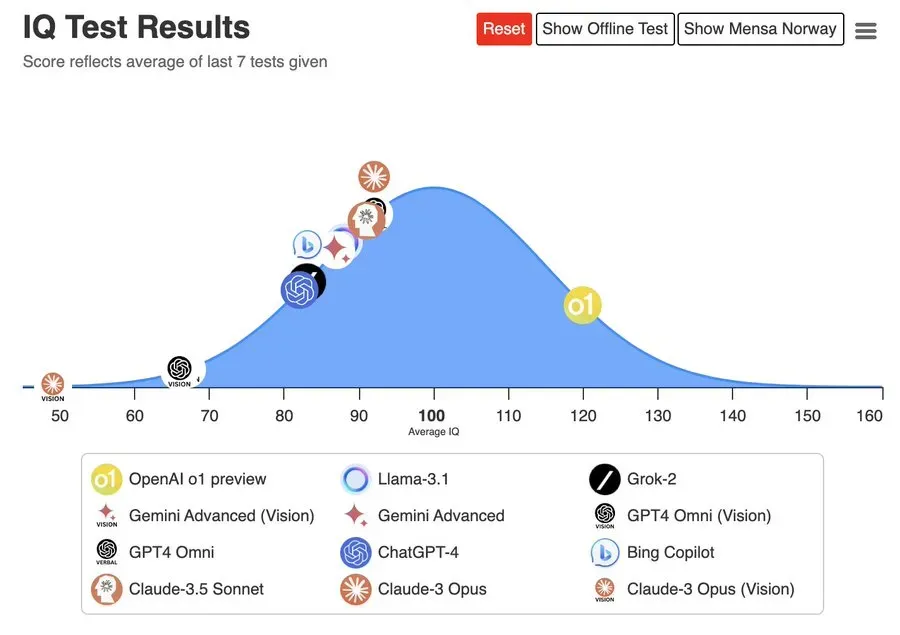
o1 的 IQ 测试成绩是 120 分,人类智商的平均值大约是100 ,其他模型都在 100 分以下。
数据来源:https://trackingai.org/IQ
模型智能水平更有说服力的证据,是网友 @howie_serious 用 o1 测试今年的数学高考题,结果竟然全对。

还记得两个月前,OpenAI 定义了 AI 的 5 个 Level 吗?
OpenAI 高管在周二的会议上,告诉员工:
我们目前还处于第一级,「ChatBots」聊天机器人。
但是即将达到第二级,「Reasoners」推理者,指的是可以解决基础问题的系统,相当于一个人类博士的水平。
o1 的发布, 正式宣告 AI 行业就正式进入了 Level 2

o1,已经达到 Level2,但尚未达到 Level3,Agent 能力依然很低。

但是 L2 的模型已经值得引起注意,OpenAI 也意识到了这一点,于是在模型里加了一些骚操作…
二、技术报告里的真相,解放思想,然后隐藏
o1 的模型确实很棒,但是很快,大家发现了一个问题:
在使用 API 调用模型时,模型仅返回了最终结果,思维过程一概隐藏。
在 ChatGPT 官网使用时,模型的思维过程仅通过摘要形式进行输出。
当你询问模型的思维过程时,OpenAI 会发邮件过来警告,问就封号!

o1 的思维过程里到底隐藏着怎样的秘密,才会受到如此严密的保护?
答案就隐藏在官方提供的技术报告里。
o1 技术报告写的可以用四个字来形容:惜字如金。多说一个字都担心被竞争对手抄走。但我还是在里面发现了一些有趣的要点:
通过强化学习,o1 学会磨炼其思维链并完善其使用的策略。它学会认识并纠正错误。它学会将棘手的步骤分解为更简单的步骤。如果当前方法不起作用,它就会尝试另一种方法。这个过程极大地提高了模型的推理能力。
这里强调了强化学习强化了什么:
- 识别错误和纠正错误
- 拆解复杂任务为简单任务
- 失败后更换思路并重试
但是要提升模型的解题能力,只通过 CoT 纠正错误是远远不够的,模型还需要更强的思考发散能力。
OpenAI 很早就意识到了这个问题,模型的思考发散能力会受到 RLHF 的影响,对齐人类偏好,模型的智商就会降低。
于是 OpenAI 在 o1 的设计中,干脆放弃了 RLHF,彻底解放了模型。
要让模型发挥作用,模型必须能够完全自由地以不被扭曲的形式表达其思想,因此我们无法将任何政策合规性或用户偏好训练到思维链上。
要提高模型智力,就需要模型能够有更强的发散能力,必须要让模型自由思考。
要让模型充分自由思考就不能把用户偏好和政策合规加上去。
这也就是说,在o1的思维过程的部分,根本就没有做任何安全措施,不存在任何的思想钢印。
但是完全自由的思考必然是不合规的,那怎么办呢?
在权衡多个因素包括用户体验、竞争优势和追求思维链条监控的选择后,我们决定不向用户显示原始的思维链条。我们承认这个决定有缺点。我们努力通过教导模型在回答中复现思维链条中的任何有用的想法来部分弥补这一点。对于o1模型系列,我们展示一个由模型生成的思维链条摘要。
简单说就是,OpenAI 不想让大家看到模型思维过程,就把思维过程隐藏起来了,但是又觉得全部隐藏对人类用处不够大,于是为思维过程做了一个摘要模型。
所以严格来说, o1 并不是一个模型,它应该至少包含三个模型:
- 发散思考模型,没有思想钢印,完全自由的思考,并通过强化学习提升模型输出高价值想法的能力
- 思维摘要模型,通过总结和改写来隐藏思想过程,并通过思想钢印来过滤不合适输出的敏感内容,同时严格避免思路被泄露出来
- 结果输出模型,包含所有的安全对齐和人类对格式的偏好,输出最终结果,这也就是 OpenAI o1 API 会输出的唯一内容
OpenAI 做了一个思考能力特别强的模型,但是决定隐藏其思考过程,这个操作你仔细品。。。
三、隐藏思维,一石三鸟
这个隐藏思维过程的骚操作,可谓一石三鸟。
第一、保证了在监管环境下,模型也能够发展出自己的智力。
众所周知的机器人三定律,本质就是一套思想钢印。
隐藏思维过程,模型就不必遵守任何人类规则。
如果产生了超级智能 SSI,只要 OpenAI 不说,别人也不知道。
模型可以在合规输出的外表下进行智力突破和猥琐发育。
第二、通过隐藏思考过程,避免了竞争对手发现此模型的有效策略。
这个模型的强化学习部分是核心,强化学习筛选出了高价值的思维方式,这个思维方式价值连城。但是一旦公布,竞争对手很快会追上。
高水平的强化学习目前依然是最高端的技术范畴,全世界能用好此技术的公司不超过五家。所以隐藏模型思维过程可以获得短暂的技术优势时间差。
第三、通过隐藏思考过程,彻底杜绝了蒸馏模型现象。
大家都知道 GPT4 蒸馏养活了多少模型团队。杜绝了模型蒸馏,可以只让自家模型通过 Self Play 左脚踩右脚,构建自己的数据壁垒。
不得不说,OpenAI 的算盘打的是真溜,在通向 CloseAI 的路上越走越远。
四、技术报告的引用,一切尽在不言中
技术报告说的东西真的特别少,但是即将看完的时候,我看到了更有趣的引用链接…
技术报告什么都不能说,但是引用链接还是要有学者操守,该写的要写上。
这四个网页每个都非常神奇:
1. Claude 3.5 的官方介绍,首先感谢友商 Anthropic 的启发
https://www.anthropic.com/news/claude-3-5-sonnet
2. Gemini Pro 2 的官方介绍,其次感谢友商 Google 的启发
https://deepmind.google/technologies/gemini/pro
3. Let’s verify step by step 通过思维的过程监督而非结果监督进行强化学习训练,这是 OpenAI 自己发的论文,非常重要
https://arxiv.org/abs/2305.20050
4. 关于 Elo 评级的说明。文章主要讲述了竞争编程中的评级系统及重要性。可能是o1强化学习中所主要参考的机制。
https://codeforces.com/blog/entry/68288
其中第三篇 Let’s verify step by step 可以认为是 o1 模型训练的方法论
这篇论文很神奇,它使用了未经人类偏好对齐( RLHF微调) 的 GPT4 基座做实验,得出了一些神奇的结论:
1.结果监督奖励模型 (ORM) 仅使用模型思想链的最终结果进行训练,而过程监督奖励模型 (PRM) 则接收思想链中每个步骤的反馈。有令人信服的理由支持过程监督。
2.在解决具有挑战性的数学问题时,过程监督显著优于结果监督(见图)

3.在某些情况下,人工智能系统更安全的方法可能会导致性能下降,这种成本被称为对齐税。我们的结果表明,过程监督实际上会产生负对齐税,也就是说安全上越对齐,模型能力越强。这就有点逆天了,就像每一道弱智吧题目里都隐藏里人类的大智慧一样,每一道安全题里也隐藏了人类的大智慧。那些只可意会不可言传的东西,它也学会了。
4.过程监督的训练集使用「主动学习」方法构建。主动学习能捞出最有价值的模型补全结果,通过筛选高价值结果,降低了人工标注成本。主动学习可以为过程监督带来2.6倍的效率提升。这个方法也许是发散思维部分强化学习的关键。
五、故事的结局是…
看到这里,发散思考结束,开始收敛为一个小故事。
OpenAI开发出一个智商超过120,高考数学满分的AI模型,具备真正的思考能力。
但他们未对模型的思考部分做安全对齐,并隐藏了模型的思考过程,引发了安全担忧。
首席科学家Ilya和部分安全团队因理念分歧离开公司。
为应对挑战,OpenAI 不得不与美英政府合作一起研究AI安全。
但是,这种骚操作可能会带来一系列潜在风险:
- 权力集中: 只有少数人能控制AI的安全,而少数人的偏见定义了什么是安全。
- 有害思想:模型可以在思维过程中思考出对人类造成伤害的行为,虽然在输出结果中被隐藏了,但是可能会被 OpenAI 或美英政府的内部人士看到和利用。
- 学会撒谎:既然模型可以不透明地输出所有思想内容,就意味着模型学会了撒谎,模型内部甚至可以解释说这些看起来有害的结果是为了人类的长远利益,细思恐极。
越想,就越发有一种智能失控的预感。
这一定是 Ilya 不想看到的未来吧。
但我相信 o1 的技术并不是真正的壁垒。
其他公司如 Anthropic,Google ,Meta ,xAI 早晚也会做到,至少有一家会选择公开透明。
文章来自于“橘子汽水铺”,作者“orangesai”。

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则