- 行业先锋
- 文章详情

企业要用好 LLM 离不开高质量数据。和传统机器学习模型相比,LLM 对于数据需求量更大、要求更高,尤其是非结构化数据。而传统 ETL 工具并不擅长非结构化数据的处理,因此,企业在部署 LLM 的过程中,数据科学家们往往要耗费大量的时间精力在数据处理环节。这一环节既关系到 LLM 部署的效率和质量,也对数据科学家人力的 ROI 产生影响。
Unstructured.io 的 CEO Brian Raymon 捕捉到了这一机会,专注为企业解决非结构化数据处理问题。Unstructured 做的事情是在 data ingestion 环节将非结构化数据提取出来,分割成更小的逻辑单元,并生成的元素级元数据,再将提取好的、转化成 JSON 格式的数据返回给用户。Data Ingestion 的精细化程度直接决定后续数据处理流程的效果,而目前 Unstructured.io 是这个环节做的最好的公司之一。
Unstructured 的优势还在于深刻理解大公司和政府的需求,CEO 的政府背景使之拥有充足的资源支持。Unstructured.io 目前已经拿下了不少大企业订单,也与美国空军和太空部队等政府部门达成了合作。
非结构化数据处理领域还在起步阶段,Unstructured.io 面临着云厂商、上下游公司和其他初创公司的竞争。未来,Multi-step agents 和多模态技术在该领域的应用,可能会带来更多机会。我们在硅谷了解到,未来几个月模型 reasoning 能力会进一步提升,multi-step agent 可能逐步实现,我们也期待非结构化数据领域能解锁更多的商业价值。
01.
Unstructured.io 的
市场机会
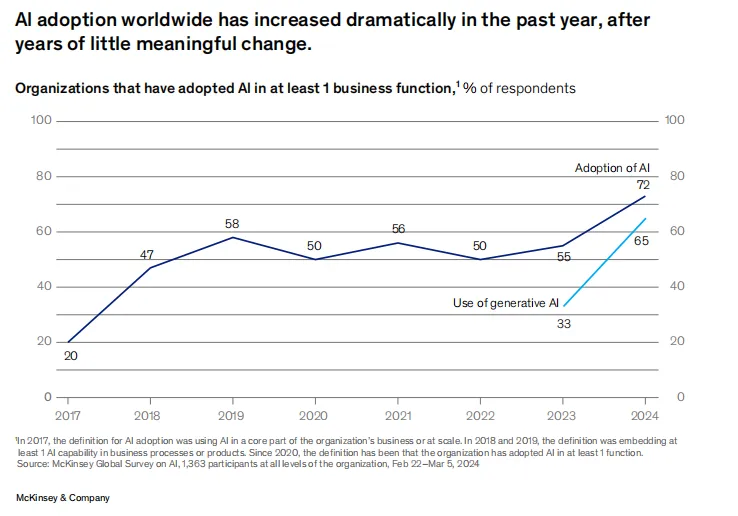
企业正在大规模采用 LLM,在麦肯锡的调研中,2023 年是 AI 在企业端渗透率最快的一年。AI 在企业侧的渗透率从 55% 增长到 72%,增长了 17 个百分点,如果把 AI 缩小到 GenAI 的范围,则速度更加惊人,过去一年从 33% 增长到 65%,增长了一倍。根据 Morgan Stanley 2Q24 的 CIO Survey,2025 年预计会继续迎来企业的大规模 GenAI adoption。
Source: The state of AI in early 2024: GenAI adoption spikes and starts to generate value, May 30, 2024 | Survey, McKinsey & Company
把 LLM 用好的前提条件是为 LLM 提供高质量的数据。企业的数据包括结构化数据和非结构化数据,其中非结构化数据占了 80%,但在 LLM 出现之前,企业 ETL 处理的主要是结构化数据。因为传统 ETL 工具不能在非结构化数据中提取足够的特征,同时传统机器学习模型受智能程度限制,对数据精确度的要求比 LLM 更高,这使得企业一直不能很好的把非结构化数据利用起来。

而 LLM 与传统的机器学习模型相比有两点不同:
• LLM 需要更多数据。企业要用好 LLM,必须要让 LLM 拥有企业内部、专业领域的特定知识。实现这一点有两个主流方式:Fine-tuning model 或做 RAG (Retrieval Augmented Generation)。Fine-tuning 将特定领域的知识 encode 到 model memory 中,RAG 则是实时的从大量数据中检索信息,帮助 model 获取最新的信息。这些知识、信息中包含了大量的非结构化数据。

使用 Unstructured 对大模型进行 finetune
二是 LLM 的 next token prediction 的机制使得它对数据的精确程度要求没这么高了,这让非结构化数据即使没有被处理的很好,也有机会被用起来了。
所以,LLM、尤其是 RAG 方法的应用大大增加了企业数据处理的工作量。Unstructured.io 的调研显示,数据科学家需要花超过 3/4 的工作时间准备数据,人力成本极高。这是因为即便 LLM 对数据的精确度要求降低了,想要做好 RAG 并不容易。“the devil is in the details.” Unstructured.io 的优势就是通过大量细致的工程化工作,处理好了 details。

What is RAG
RAG 的工作流大致分为:数据提取及处理 (data ingestion and preprocessing) → 索引创建 (index creation) → 检索 (retrieval) → 回答生成 (answer generation)。
在 data ingestion 环节,需要将数据提取后分割成更小的逻辑单元(称为元素)、生成的元素级元数据,并转化成 JSON 等结构化格式。这一步的精细程度如何,直接决定了后续数据清理、数据分块、生成分块摘要以及 embedding 的效果,这是难点,也是 Unstructured 的优势所在。用传统的方式清理数据,需要编写大量的正则表达式,自定义 Python 脚本去识别不需要的内容(如页眉、页脚、重复模板或无关章节),但是 Unstructured 做到了每个文档元素都有明确的分类标签或元数据标记,数据科学家可以直接使用这些元数据快速识别出需要的内容。
Unstructured 能够依据逻辑和上下文界限的智能分块(Chunking),也是因为在数据分割阶段做的足够精细化。在做数据 embedding 时,developer 会先将源文件分割成若干块,因为这样可以让 embedding 做的颗粒度更细,检索更准确;同时 LLM 的上下文窗口有限,每次都处理整个文档的成本过高,也会影响输出效果。传统的 chunking 方式是根据字符长度将文档分成大小相等的部分,但是这种方法不能反映文本的逻辑。而 Unstructured 因为对数据分割的足够精细,分类了文档元素,所以可以通过内容逻辑来分块。它还会生成分块摘要,也能做到识别并单独提取文档文本、图像和表格等元素。这最终实现了更好的RAG效果,生成更好的答案。

Unstructured Chunking 方式
和传统 Character Splitting 的不同
Embedding: 使用 embedding models 将文本表示为向量字符串(一个浮点数列表),其中编码了底层数据的语义信息。embeding 允许根据语义相似性而不仅仅是关键字匹配来搜索文本,是许多 LLM 应用程序的核心。这一流程中,开发者自己选择好合适的切分技术(chunking techniques)和嵌入模型(embedding models)后,Unstructured 平台会自动处理模型的调用、部署和运行,生成的嵌入向量会被整理、输出,存储在数据库,用于后续的分析任务。
02.
什么是 Unstructured.io
Unstructured.io 是前美国中央情报局分析师 Brian Raymond 2022 年 7 月成立的。创立 Unstructured 之前,Brian Raymond 和创始团队均在 NLP 领域的公司工作,他们发现了同样的问题:由于无法处理非结构化格式的数据,客户无法很好的应用 AI 模型。
所以,Unstructured.io 成立后首先发布了开源的非结构化数据提取工具,将企业的非结构化数据解放出来。同时,Raymond 的政府背景很深厚,Unstructured.io 得到了美国空军、美国特种作战司令部的支持,与大企业和美国政府合作打磨商业化版本的产品。
上文已经提到过,Unstructured.io 目前专注的是 Data injestion 这一个环节,帮助企业从各种数据源(以 PDF 为主,还包括 PowerPoints、Google 文档、Slack 消息、音频记录等)提取出所需的内容,进行细致的分类后,将提取好的、转化成 JSON 格式的数据返回给用户。用户可以结合其他的工具和库对这些数据进行进一步处理,应用于 LLM。
企业中的非结构化数据处理以 PDF 为主,是因为数据大多数场景下会被转化为 PDF 格式储存,包括文章、纪要、财务报表等等。而从 PDF 中提取数据一直是数据科学家非常头痛的工作,因为经常会遇到表格被锁住、格式混乱、内容无法访问一系列问题。
不过为了获取更广阔的市场,Unstructured.io 也搭建了端到端的企业级平台,支持整个 Workflow。
产品矩阵
Unstructured.io 通过开源起步,不断丰富产品形态,目前产品包括 SaaS、Serverless 和 Marketplace API,以及企业级平台,满足了不同客户的需求。
开源的 Python 库:
开源的 Python 库是 Unstructured 最早发布的产品,官网上显示已经被下载了六百多万次,被 4.5 万个组织使用,这其中包括三分之一的财富 500 强公司。
核心组件包括数据提取器、文档分割器和数据转换器。
• 数据提取器负责从各种格式的文档中提取内容,如 PDF、Word 等。
• 文档分割器能够将文档内容细化为更小的逻辑单元,便于进一步分析。
• 数据转换器将提取和分割后的数据转换成标准化的格式(以 JSON 为主),以便下游应用和模型使用。

开源 Python 库适合用于产品的原型开发,目前仅进行基础的维护工作,自2024 年开始就不再更新商业版推出的新功能了。更高级的 chunking 方式、更多格式的文件和图像处理等等功能商业版用户才能使用。企业要是想要获得更好的性能,还是要购买商业版本。
商业版 API:
商业版 API 分为 SaaS API, Serverless API, Marketplace API,核心组件与开源产品类似,但是支持更多的 chunking 方式、文件种类,提供更好的性能。
• SaaS API 今年 1 月份推出,由 Unstructured 托管,用户只需调用 API,无需管理底层基础设施。目前已有超过 1000 个付费用户了,适合需要单批次处理的中小企业或个人用户。
• Serverless API 今年 6 月份推出,也是由 Unstructured 托管,但与 SaaS 版不同,Serverless 使得用户可以更灵活地处理高并发请求。适合需要高弹性、按需扩展的场景,比如不定期的大批量处理,或需要根据负载自动调整资源的应用。
• Marketplace API 今年 2 月份推出,由客户自行托管在 AWS 或 Azure 等云平台上,完全在公司内部基础设施内处理数据。它适合数据敏感性高的大企业,集成了多种企业级别的数据连接器。
Enterprise Platform:
Enterprise Platform 是一个企业级、低代码、交钥匙的ETL全流程解决平台。它提供可视化的用户界面,让用户可以在不编写代码的情况下创建完整的ETL工作流。商业模式包括 “即用即付 “选项和订阅计划,也可以为企业定制解决方案。

它适合拥有大量数据的企业级公司和高增长公司。能力包括:
• 支持从 10 个数据源提取文档内容(如 Azure Blob Storage、S3、Google Drive 等)。
• 标准化输出传送到10个目标数据源(如 Pinecone、Weaviate、S3、Postgres 等)。
• 通过 workflow 连接源和目标,支持运行和调度工作流。
• 监控工作流状态。
Unstructured 的产品还处于早期阶段,未来有大量的功能值得开发。目前的产品规划就已经涵盖了很多功能:包括集成更多源和目标连接器、增加音频和图像处理功能、支持用户自定义 embedding 模型、集成 Azure AI Document Intelligence 和 AWS Textract、增加数据存储和向量同步能力,推出新一代表格和表单提取模型等等。
产品优势
根据分析产品和客户访谈,我们发现 Unstructured.io 最突出的优势有以下几点:
1. 低延迟
企业反应 Unstructured 大大提升了处理非结构化数据的效率。这是因为处理多个不同类型的文件时,传统的方法是全部转化成图像,然后再通过 OCR 统一流程处理这些图像,速度很慢,推理成本也很高。而 Unstructured 对不同的文件类型(如 PDF、Word 文档、Excel 表格等)都提供了专门的数据提取方法,可以直接处理原始文件,避免了将文件转换为图像的步骤,更为高效。官网表示 Unstructured 的解决方案比将文件转换为图像,再用 OCR 的方法快了约 100 倍。
2. 能处理的文件类型更多、更准确
很多企业评价 Unstructured 相比竞品,可以从更多类型的文件格式中提取数据,而且提取文本时保持原有的语义。市场上还没有能达到类似准确程度的替代工具。
这是因为 Unstructured 对文件内容的分类能力更强。一些传统的预处理工具(如 Azure Document Intelligence)只能对一些特定的文件类型,分类的元素层级也是有限的,比如只能识别正文和标题。但是 Unstructured 分类更细致,生成 metadata,而且成本还更低。

分类细致的好处在于方便做下一步的 cleaning、可以采用混合搜索和基于metadata过滤的方式实现更加精确的内容控制(比如只处理正文,图像、文本分开处理),并可以按语义分块,这是 Unstructured 高准确性的关键要素。不过 Unstructured 也没有覆盖所有场景,客户认为还需要覆盖更多的数据格式。
3. 广泛的集成
Unstructured.io 的开放源代码库包含 25 多个源连接器和 10 个目标连接器,尽量覆盖了用户的所有使用工具和场景。如与 LangChain, Llamaindex 等集成,进一步方便的 GenAI 应用的开发。Unstructured 还将这些打包到了商业版企业平台中,企业平台是一套交钥匙的解决方案,有一个无代码用户界面仪表板,可以直接创建和管理 RAG 工作流。
但综合来看,Unstructured 的这些优势更多的是因为起步更早、工程层面做的更细致,很难说是绝对的竞争壁垒。
客户及商业化
虽然有开源版本,但 Unstructured.io 在付费客户获取上做的很好,在 2024 年 3 月完成 B 轮融资时,其 1 月份推出的商业版 SaaS API 就有超过 1000 个付费客户了,其中包括不少大型企业以及政府订单。
根据客户访谈,我们发现很少有客户会选择 Enterprise platform 这个 ETL 全流程解决方案,更多的是从开源转向商业版 API,仅仅将 Unstructured.io 用于 data injestion 环节,集成在企业已有的工作流中,与其他工具(如 Milvus、Elasticsearch、LlamaIndex、LangChain 等)一起使用。比如 Qualcomm 采购了商业版 SaaS API,用于从财务文件和产品数据表(PDF、Word、Excel)中提取信息。而 Adobe 将 Unstructured.io 用于内部模型训练和微调的数据准备 pipeline 中,也用于 PDF 和 Photoshop 中的摘要和问答功能的实现。
Unstructured.io 的价值体现在节省数据处理的时间和成本,客户访谈中,大部分客户已经从开源产品转化为付费用户,付费从四位数/年~六位数/年不等,部分客户有增加预算的计划。如 Adobe 预计会在 5000 美元/年的基础上有 2-3倍的增长,IQVIA 也表示试点阶段投入相对较低,如果全面投入使用成本可能在 500 万到 1000 万美元之间。
这是因为商业版本准确性更强,覆盖的文件类型更多,也提供企业级的部署支持,Unstructured 从开源到商业化的过程是相对顺畅的,我们预计未来的收入会持续提升。Unstructured.io 在多个行业(如新闻、金融、法律、医疗等)都有应用案例,表明它的数据提取能力的通用性还是很强的。
不过客户也普遍认为 Unstructured 面临着来自大型云厂商、上下游公司以及其他创业公司的潜在竞争。企业是否会迁移到其他产品很大程度上取决于使用深度,目前来看,迁移成本是较低的。针对特定行业领域的需求提供针对性的解决方案是 Unstructured 建立壁垒的潜在机会。
团队及融资情况
团队
Unstructured.io 的 Founder 及 CEO Brian Raymond 早期是一名政客,曾在美国中央情报局(CIA)担任情报官员,后来在白宫负责伊拉克和 ISIS 的外交政策。在 ISIS 于伊拉克和叙利亚迅速崛起期间,Raymond 与奥巴马总统和拜登副总统紧密合作。
后来,他加入初创公司 Primary AI,为公共部门和国家安全领域提供精确、安全的 NLP 解决方案。Brian 深入研究了如何基于 Transformer 构建知识图谱和企业工作流。他意识到数据预处理在 AI/ML 项目中,其是在处理复杂的政府内部文件时非常重要。这使他决定创立 Unstructured.io,为企业和政府简化数据准备过程。
Unstructured.io 的团队由开源社区、大型企业和美国国防情报机构的技术专家组成。在商业化产品推出后,Brian 搭建起了销售团队。目前,Unstructured 有一支技术、市场和客户服务领域实力都很强的团队,有能力承接大型企业和政府机构的需求。

融资
Unstructured.io 获得了累计 6500 万美元的投资,投资方包括 AI 生态上层公司 LangChain 和 databricks,可以看出它在 Gen-AI 生态系统中的重要性是被认可的。

03.
市场竞争
非结构化数据的提取是企业数据处理工作流中的一个环节,如果市场机会足够大,工作流中的玩家都有动机、也有机会延伸到这个场景。根据客户访谈分析,我们认为 Unstructured.io 主要面对来自大型云厂商、上下游公司及其他初创公司的潜在竞争。
• 大型云厂商
根据客户访谈,我们得知 Amazon、Azure 等云厂商也在尝试开发提供非结构化数据处理能力的工具,但由于这个领域技术比较新,巨头行动慢,所以至今还没有发布可匹敌 Unstructrued 的产品。
云厂商的优势很明显。产品组合上,云厂商可以通过与现有的产品(如存储解决方案、compute 和数据分析工具)集成,为客户提供一站式服务。销售网络上,大型云厂商拥有庞大的客户基础和资源,交叉销售给客户,销售路径也更顺畅。云厂商还能通过规模效应降低成本,提供更具竞争力的定价策略。
但 data ingestion 这个环节可能并不是云厂商的 priority,云厂商不会拿出足够的预算和最好的团队去开发、优化这个产品。Unstructured.io 具有更强的产品专注性和深度,能够提供更优化的解决方案。目前 Unstructured.io 在数据提取的准确性面上有优势。作为创业公司,在客户服务、定制化需求响应速度上也更为灵活和即时。
• 上下游公司,如 Vector Database
客户访谈表示许多向量数据库公司也在尝试开发自己的处理非结构化数据的 API,比如 Milvus、Chroma,Pinecone。如果向量数据库发布类似产品,用户将能够在同一平台内完成从数据预处理到存储、检索的全过程。不过这些公司尚未完全发布产品,具体能力未可知。
• 提供非结构化数据处理工具的初创公司:
这些初创公司专注在不同的领域,如 Llamaindex、Hammerspace 提供相对综合性的数据处理工具,Clarifai 专注图像和视频处理。

其中 llamaindex 的非结构化数据提取工具 llamaparse 与 Unstructured.io 直接竞争。llamaindex 的 end-to-end 的开源生态对 Unstructured.io 存在一定的挑战。我们在 Unstructured.io 的 Slack 中观察到,很多用户有集成Llamaindex 的需求,llamaparse 也做到了类似 Unstructured.io 的产品准确性。这也进一步证实了非结构化数据 injestion 可能并不具备明显的技术壁垒,更多的是工程上优化的问题。
我们认为两家公司未来可能会获取不同的客户群,与其他初创公司相比,Unstructured.io 的市场定位更专注于大型企业和政府部门,这些领域对数据安全性、准确性和专业化需求更高。而 LlamaIndex 可能更多面向需要快速集成和灵活性的中小型企业和开发者社区。
04.
结论与猜想
Unstructured.io 目前的核心优势有两点。
其一是先发优势和团队的工程能力,使得 Unstructured.io 的 data ingestion 的产品效果领先绝大部分竞争对手一个身位。但这个优势很容易被资源更充足的大厂,或技术实力更强的创业公司追平,如 llamaprase 已经达到了类似的效果。
其二是团队对大企业和政府需求的理解足够深,拥有丰富的政府资源,这使其在商业化上保持领先。Unstructured.io 的核心团队由政府官员、大企业高管、AI Researcher 组成,资源硬核且懂大企业的需求。CEO Brian 的政府资源以及政府在非结构化数据处理上的旺盛需求也使得 Unstructured.io 能获得大量政府的订单。
单点的产品功能优势难以建立起长期的竞争壁垒,Unstructured.io 面临着大型云厂商、上下游公司,以及已经搭建了完整 RAG 开源工具的初创公司如 llamaindex 等公司的竞争。目前RAG处于发展早期,还难以预判未来的格局。不过我们对 Unstructured.io 的发展有较强的信心,llamaindex 的开源框架容易被“露天开采”,Unstructrued.io 也在搭建 end-to-end 的 RAG 产品。如何不断提升产品效果,服务好企业的需求才是商业化的关键。
非结构化数据处理未来也有很多潜在的变化可能,我们会对该领域的发展保持持续关注:
其一是 Multi-step Agents 的发展有可能改变目前的非结构化数据处理方式。Raymond 在访谈中提到,Agents 能够自动化数据检索和处理,还能通过多步推理显著提高准确性和效率。这种转变将减少对数据预处理的依赖,赋予 LLM 更强的处理复杂任务的能力。目前使用 LLM 来执行非生成性任务(如数据转换)的技术还没实现,但随着模型 reasoning 能力的提升有一定的发展潜力。
另外,多模态 LLMs 会扩展数据处理的范畴,可能会改变 RAG 和 ETL 的工作流程。随着模型能够处理和解析图像、视频等多种媒体,企业可能需要重新设计数据转换和检索 pipeline,更好地利用这些新能力,这也为创业公司带来了机会。
文章来自于“海外独角兽”,作者“haina”。
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则