- 行业先锋
- 文章详情

基于开源Agent框架,可自动解决复杂数据科学问题的Agent来了!
具体来说,Data Science Assistant(以下称DS Assistant)是基于Modelscope-Agent框架开发的数据科学助手。
有了它,我们只需给需求,这个助手就能自己跑完探索性数据分析(EDA)、数据预处理、特征工程、模型训练,模型评估等步骤。
当然,除了本文将重点提到的DS Assistant,它背后的Modelscope-Agent框架也值得说道。
这个框架由阿里开源,主要特点包括:
- 可通过vllm、ollama等工具接入各主流开源模型,也可以直接调用模型API;
- 提供RAG组件支持开发者快速接入知识库;
- 工具生态丰富,支持大量的Modelscope社区模型作为工具,也支持直接调用langchAIn的工具,还接入了各类常用的工具,如web-browsing、文生图、code-interpreter等;
更妙的是,Modelscope-Agent框架允许开发者无需编码即可交互式地创建Agent助理。
这不,啪的一下,咱们的数据科学助手“诞生”了~
复杂数据科学任务自动化
实现复杂数据科学任务自动化一直存在挑战。
传统的ReAct(Reasoning and Action)框架对于简单的任务比较有效,但是有以下缺点:
- 每次工具调用都需要一个LLM调用。
- LLM一次仅计划1个子问题。这可能会导致任务的轨迹更加不可控,因为它不会被迫“推理”整个任务。
而DS Assistant使用了plan-and-excute框架,这是一种新兴的Agent框架,通过明确计划和执行步骤高效完成复杂任务。
langchain官网对Plan-and-execute Agent的描述:https://blog.langchain.dev/planning-agents/
具体而言,其工作流程包括以下几个步骤:
1、任务计划:Agent接收用户输入的任务描述,进行语义理解,将任务分解为多个可执行子任务。
2、子任务调度:基于任务之间的依赖关系和优先级,智能调度子任务的执行顺序。
3、任务执行:每个子任务分配给特定的模块执行。
4、结果整合:汇总各子任务的结果,形成最终输出,并反馈给用户。
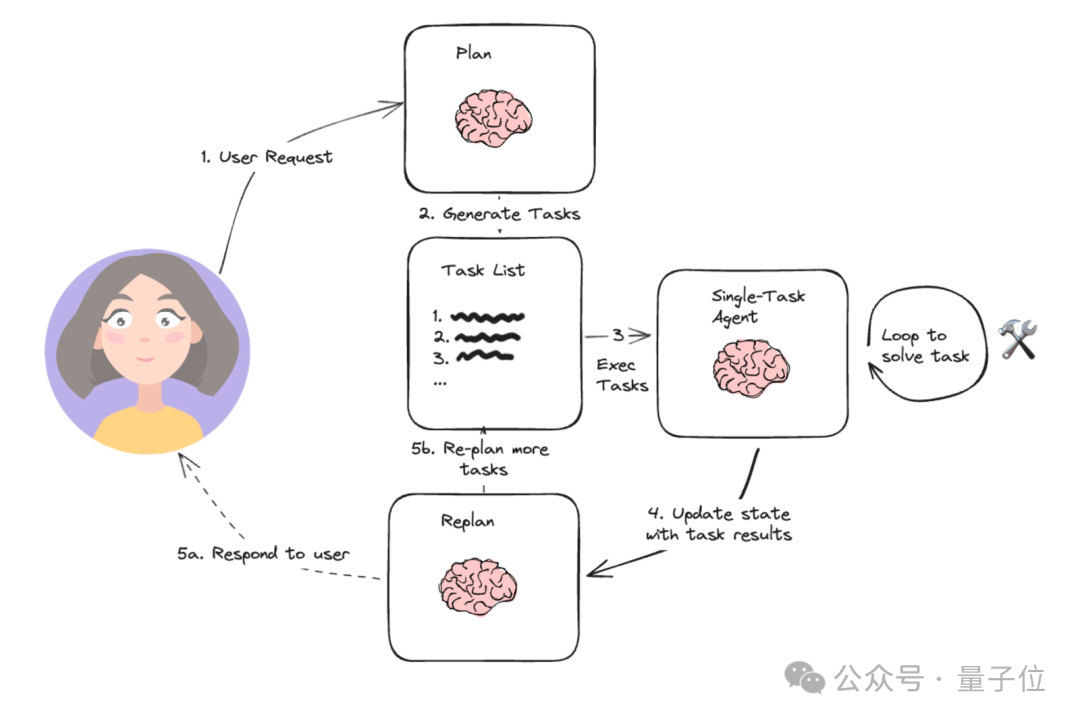
基于上述框架,咱们接着看整个系统架构,DS Assistant整套系统有4个主要模块。

先说右侧的DS Assistant,它作为整个系统的大脑,负责调度整个系统的运转。
而Plan模块负责根据用户的需求生成一系列Task列表,并对Task先后顺序进行拓扑排序。
在这一阶段,DS Assistant根据用户输入的复杂数据科学问题,自动将其分解为多个子任务。
这些子任务根据依赖关系和优先级被组织和调度,确保执行顺序符合逻辑且高效。

接下来到了Execution模块,负责任务的具体执行,保存任务执行结果。
在这里,每个子任务被具体化为可执行的操作,如数据预处理、模型训练等。

最后是Memory management模块,负责记录任务中间执行结果,代码,数据详情等信息。
在所有Task执行完成后,DS Assistant会将中间数据的执行情况 ( 包括每个task生成的代码和结果,消耗token数,任务时间 ) 保存为文件。
案例实战
下面,我们以一个具体的例子来了解DS Assistant的执行过程。
我们选用Kaggle上的一个比赛任务ICR – Identifying Age-Related Conditions作为示例:
该任务是一项机器学习任务,主要目的是通过分析各种数据(如医疗记录、基因数据、生活方式数据等),识别与年龄相关的健康状况。
最终结果将用来帮助医疗专业人员及早发现老年人群中常见的健康问题,并提供个性化的预防和治疗方案。
废话不多说,我们这就开始~

首先,对于选用的LLM,我们需要配置一下。
我们引入MetaGPT的Data Science工具和Tool Recommender,可以根据任务类型向DS Assistant推荐合适的数据科学工具。
接着,我们需要将任务的具体要求传给DS Assistant。需要注意的是,在要求中需向DS Assistant指明数据文件的路径:
from modelscope_agent.agents.data_science_assistant import DataScienceAssistant
from modelscope_agent.tools.metagpt_tools.tool_recommend import TypeMatchToolRecommender
llm_config = {
'model': 'qwen2-72b-instruct',
'model_server': 'dashscope',
}
tool_recommender = TypeMatchToolRecommender(tools=["<all>"])
ds_assistant = DataScienceAssistant(llm=llm_config, tool_recommender=tool_recommender)
ds_assistant.run(
"This is a medical dataset with over fifty anonymized health characteristics linked to three age-related conditions. Your goal is to predict whether a subject has or has not been diagnosed with one of these conditions. The target column is Class. Perform data analysis, data preprocessing, feature engineering, and modeling to predict the target. Report F1 Score on the eval data. Train data path: ‘./dataset/07_icr-identify-age-related-conditions/split_train.csv', eval data path: ‘./dataset/07_icr-identify-age-related-conditions/split_eval.csv' ."
)
在Plan阶段,DS Assistant会根据用户需求生成任务列表,将整个数据处理流程进行分解,接着对任务列表进行按顺序处理。
可以看到,DS Assistant生成了5个任务,分别是数据探索,数据预处理,特征工程,模型训练和预测。

然后这5个任务进入了Execute阶段,下面咱们挨个看一下。
Task 1: 数据探索

可以看到生成的代码在执行时报了如下错误,原因是没有引入numpy包。

DS Assistant根据报错进行了反思,并重新生成代码并执行,成功输出数据探索的结果。


最后,code judge会对代码进行质检,确保本次生成代码逻辑正确。

Task 2: 数据预处理
在数据预处理阶段,DS Assistant分别对数值型数据和类别型数据进行了合适的缺失值处理,并清除了ID列。

Task 3:特征工程
在修复了两次错误后,DS Assistant对数据进行了特征工程的处理,对类别型变量进行编码。
同时对之前定义的categorical_columns变量进行了更新,去除了ID列。

Task 4:模型训练
DS Assistant主动安装了合适的依赖,并选择了多个模型(随机森林,梯度提升,逻辑回归)进行训练,并选择了结果最好的模型。



Task 5:模型验证
DS Assistant选择了训练集中F1分数最高的模型对验证集进行测试,并计算了这个模型在验证集上的F1分数,成功地完成了任务。

执行完以上任务后,DS Assistant支持将运行结果保存为Jupyter Notebook类型的文件,并记录运行的中间过程。

△Jupyter Notebok

△中间过程记录JSON文件
实验效果
我们使用ML-Benchmark作为测试集(指路论文“Data Interpreter: An LLM Agent For Data Science”),分别从Normalized Performance Score (NPS) ,total time,total token三个维度对DS Assistant效果进行评测。
其中NPS是一种将不同任务或模型的性能指标标准化的方法,使得不同指标之间可以进行比较。
它的计算通常涉及以下步骤:
步骤1:确定指标优化方向,判断性能指标是“越大越好”还是“越小越好”。
步骤2:规范化计算。如果指标是“越大越好”(如准确率、F1分数、AUC),NPS等于原始值;如果指标是“越小越好”(如损失值),则需要将原始值映射到接近1的较高NPS值。
规范化后的性能得分范围通常是0到1,其中1表示最优性能,0表示最差性能。
实验任务详情和结果如下( 绿色代表当前任务下最优指标 ):


可以看到,在部分复杂的数据科学任务上,DS Assistant在规范化性能得分(NPS),任务时间,消耗token数的指标上取得超过开源SOTA的效果。(其中开源SOTA效果指MetaGPT实测值)
完整实验日志:https://modelscope-agent.oss-cn-hangzhou.aliyuncs.com/resources/DS_Assistant_results.zip
总结
对不同的人来说,DS assistant有不同作用:
- 不熟悉数据分析流程但是又有需要的同学,可以快速根据生成的任务以及处理过程,了解处理数据的思路,以及技术点。
- 对于了解数据分析流程的同学,可以通过详细的描述,来影响数据处理的方法,方便做不同的实验参照比较。
- 对于所有人,可以自动化的快速实现对于当前手上文件的更深层次的理解,仅需提问即可。
下一步,DS assistant将从三个方向展开优化:
1、进一步提高任务执行成功率:
a)对于Code Agent来说,传入信息量过大(报错信息,中间数据信息,已生成代码信息)会导致模型生成代码正确率下降,可以在未来考虑使用LLM进行总结,对信息进行筛选。
b)同一个Task可进行进一步的分解,以降低对LLM推理能力的要求。
2、对话交互式,可以将任务和任务的执行展示分开,通过对话的方式推进任务,并影响执行结果。
3、支持批处理相同任务多批文件的场景。
更多细节可进一步查看Modelscope-Agent官方仓库中Data Sciecne Assistant示例。
https://github.com/modelscope/modelscope-agent/blob/master/examples/agents/data_science_assistant.ipynb
文章来源于“量子位”,作者“魔搭社区”

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则