- 行业先锋
- 文章详情

大模型今天所展示出的强大能力,源于背后海量数据,为其注入了丰富的人类知识。如果将大模型视为正在疾驰的科技列车,数据语料便是珍贵的“燃料”。其中,语料质量的提升对模型性能取得阶段性突破至关重要。
然而一个现实情况是,高质量语料正在被急速消耗。国内大模型厂商所面临的语料短缺问题十分严峻。
以中文语料为例。中国工程院院士高文指出,当前全球通用的50亿大模型数据训练集中,中文语料占比仅为1.3%,其数量和质量上同英文等其他语言相比存在明显不足。“沉睡”在报告、论文、报纸等文档内的大批高价值语料数据,由于其复杂的版面结构,制约了大模型的训练语料处理能力,无法被轻易解析并提取。
解决中文数据不足和质量问题,处理多样化数据,仍是各厂商面临的一大挑战。
为了帮助企业应对数据局限问题,日前,合合信息在WAIC 2024上发布了用于大模型语料训练的“加速器”产品——TextIn智能文档处理平台。
在训练前期阶段,使用“加速器”文档解析引擎,破解书籍、论文、研报等文档中的版面解析障碍,为模型训练与应用输送纯净的“燃料”;同时,“加速器”搭载了文本向量化模型,以解决大模型“已读乱回”的幻觉问题。
合合信息的思路是,从“炼丹”源头的燃料出发,通过标准化平台进行语料结构化,提高数据预训练效率,帮助大模型厂商达成有效的模型性能提升和迭代。
处理复杂语料
合合信息此次发布的大模型“加速器”TextIn智能文档处理平台,由TextIn文档解析、TextIn Embedding(文本向量数据模型)以及OpenKIE三大工具组成。
目前,无线表、跨页表格、公式等复杂元素的处理,仍是大模型语料清晰的“拦路虎”。
以银行常见的基金对账单托管业务为例,市面上基金公司众多,各家企业的账单样式都不相同,加上复杂的表格呈现形式,要将数据从非结构化图文信息中抽取,并整理成模型训练需要的形式,往往十分耗费人力和时间。
失之毫厘、差之千里,一个单元格的理解问题,可能导致表格整体识别的结果发生巨大误差;同时,表格的还原准确率,也直接影响了模型问答的效果。
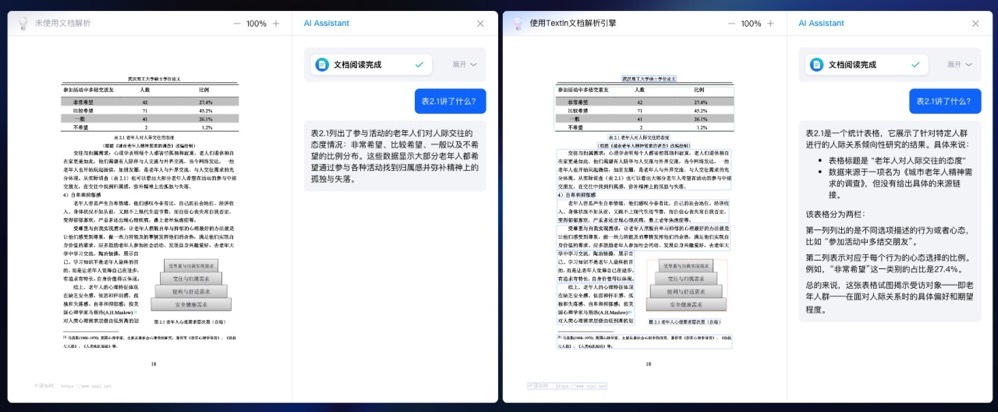
TextIn文档解析在文本、表格、图像等非结构化数据的表现上,最快1.5秒就能完成百页长文档的解析;不仅速度快,同时还具备理解能力,可以智能还原文档的阅读顺序。
大模型使用文档解析引擎之前(左)和之后(右)的效果对比。结果表明,使用后大模型具备了更快速、优秀的文档要素分析、表格内容识别能力。
面对多类型样本问题,合合信息在TextIn文档解析的算法阶段,就很注重图表数据训练。当前,TextIn文档解析工具可以将柱状图、折线图、饼图、雷达图等十余种常见图表,以及任意格式文件 “还原”,并其拆解为Json(轻量级的数据交换格式)或Markdown(轻量级标注语言)格式。
经拆解后的数据语料清晰易懂,可以让大模型更好地理解图表数据,进而学习商业研报和学术论文等专业文档中的论证逻辑。同时,在图表不显示具体数值的情况下,TextIn文档解析也可以仅依据坐标轴区间,估算出具体数值。

文档解析引擎基于坐标轴区间,对不显示具体数据的图表进行数值估算。
另一方面,大模型或许在通用问答中生成表现很好,但就现阶段来看,面对专业领域问题,大模型仍存在局限性,容易出现“一本正经地胡说八道”的幻觉,稍不注意,便可能带来严重的影响。
经测试,使用合合信息的TextIn Embedding模型(文本向量数据模型)后,能提高大模型信息搜索和问答的质量、效率和准确性。
TextIn Embedding模型是一个acge_text_embedding模型(以下简称:acge模型)。就像“指南针”一样,通过大量中文语料的深入学习,acge模型可以迅速对全文进行查找,找到目标信息定位,并将有效的文本特征提取出来,准确完成分类和聚类任务。
与其他开源模型相比,acge模型体量较小,占用资源少,1024输入文本长度能满足绝大部分场景的需求。
虽然大模型支持的token数量在持续增加,令其具备了“短暂记忆”的能力,但仍会出现灾难性遗忘的问题。针对这一问题,acge模型引入了持续学习训练方式。
相较之下,acge模型支持可变输出维度,让企业能够根据具体场景去合理分配资源,从而提升了模型系统的性能和体验。
以大模型厂商实际引用场景为例,在未引入向量数据库时,如果厂商采用的是分布式系统的开源方案,其缺点在于,随着语料增长到一定规模时,分布式存储很快就会遇到瓶颈;同时,每天上亿的数据处理量,按照传统单线程序处理方式速度有限。引入acge模型后,其文档的整体处理速率可得到显著提升,同时在数据齐备的情况下,还能消除部分幻觉、多文档元素识别、版面分析等问题。
OpenKIE是一个可用于图像文档的信息抽取工具,其中包括了字段抽取、列表抽取和元素抽取三种模式。
客户只需创建好文档类型,设置需要提取的字段并上传文件,OpenKIE就能自动抽取文档中所需信息,并直接应用、或导入到其他系统中使用。

合合信息文档解析引擎与常规OCR引擎适用对比
比如在大模型文档处理场景中,合合信息与百川智能合作,共同破解困扰大模型产业已久的多文档元素识别、版面分析难题,将对百页文档的整体处理速率提升超过10倍。
合合信息智能创新事业部总经理唐琪告诉硬氪,目前,TextIn智能文档处理平台可覆盖金融、医学、财经、媒体等47个场景,共3200余类文档;已被用于百川智能等多家头部大模型厂商的预训练流程,同时也积累了小批量开发者用户。
泛场景、通用的工程化能力
就目前来看,几乎大模型每一次能力提升,其预训练数据的数量、语料质量、领域类型等多维度都起到了关键性作用。
在数据处理方面,国内大部分厂商选择的方案主要有两类:一类是交给提供基础设施服务的第三方公司,例如合合信息的TextIn智能文档处理平台、Amazon Textract文本提取服务;另一类是以银行、券商等垂直赛道企业为代表,在传统OCR算法基础上叠加训练内部模型。
唐琪告诉硬氪,“从调研来看,企业选择供应商的标准无非就三个维度——快、稳、准。”
快,即文档解析引擎的速度要快;根据合合信息测算, TextIn智能文档处理平台保持在1.5秒内的解析时长,而当前市场上部分同类型工具的速度在其3-5倍。稳,指面向大批量、复杂格式的语料,例如PDF文件、表单等,是否都能兼容并进行高准确度的解析工作。准,即能否将文档信息精准还原为表格。
当前,高质量、经梳理过的语料短缺是一大问题,“特别是中文数据更是稀缺,”唐琪说到。
国内外大模型数据集主要为英文,均源于许多开源数据集进行训练,如Common Crawl、RedPajama、BooksCorpus、The Pile、ROOT等。这部分数据虽然量多,但质量上却良莠不齐。一大优质的中文语料数据,沉睡在报告、论文、报纸等文档里。
从获得海量数据到高价值数据,预训练阶段的语料处理十分关键。这意味着,作为一个平台型产品,向大模型厂商和开发者“递铲子”,其基础的工具能力是否足够扎实,关系到种子用户的购买意愿。
唐琪经历过这样一件事。有位从事二手奢侈品贸易的商家手上积攒了大量小票,为了计算利润,他每次需要人工将售价减去原始价格后,将最终结果录入后台,整个过程涉及的公式计算很复杂,包括数额差价、各款式的库存等问题,传统OCR模型无法应用。对方找到唐琪后,通过在加速器平台上调节了小参数,很快需求得以解决了。
这只是一个细分场景中极为精细的小问题。在大模型时代,平台工具的本质形态,不同于单层的私有化部署逻辑,更强调面向泛场景、通用的工程化能力。
基于这一思路,合合信息在产品设计阶段提前做了几件事。首先是场景前置,在未个性化阶段提前给模型补充大量优质的垂直领域Know-how,比如金融、法律、教育等,关注特定行业中的普遍痛点,基于用户诉求在产品设计时提供解决方案,进而提高大模型加速器在核心应用场景中表现能力。
二是专注产品化,不只对客户提供通用场景的API,而是提供更多工具型产品,降低应用门槛,做到开箱即用,这对技术资源较为薄弱的传统企业、中小创业公司或个人开发者来说非常友好。
大模型变革的浪潮里,以数据为中心,成为行业人士从事大模型研发和应用的共识。具体到实践层面,大模型上游阶段在文本解析、逻辑版面、文档问答等方面,仍有很多的提升工作可以做。
未来,合合信息将重点瞄准金融、医疗等行业推出垂直领域产品,同时面向开发者推进内测计划,吸纳更多用户参与到产品共创和优化中去。
文章来自于“36Kr”,作者 “黄楠”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则