- 行业先锋
- 文章详情

智东西7月24日消息,Satbility AI于7月19日在Arxiv上分享了Stable Audio Open的研究论文,公开了该模型背后的技术细节。
Stable Audio Open是StabilityAI于今年6月推出的开源文本转音频模型,可免费生成长达47秒的样本和音效,还可生成44.1kHz高质量立体声音频,并且能在消费级GPU上运行。除了免费、开源,该模型还注重保护创作者版权,在数据训练中尽力避免伦理道德问题。
论文透露,Stable Audio Open是StabilityAI于今年3月推出的商用Stable Audio 2的变体模型,整体架构保持一致,但在训练数据的采用和部分架构上采取了调整,关键架构由自动编码器、基于T5的文本嵌入以及扩散模型(DiT)构成。
论文地址:https://arxiv.org/html/2407.14358v1
一、3个关键架构提供支持,免费生成44.1kHz高质量立体声短音频
Stable Audio Open引入了一种文本转音频模型,有3个主要架构:
- 自动编码器:将波形数据压缩到可管理的序列长度;
- 基于T5的文本嵌入;
- 基于transformer的扩散模型(DiT):在自动编码器的潜在空间中运行。
自动编码器是一种神经网络架构,由编码器和解码器组成,编码器将输入的数据压缩成一个较小的潜在空间表示,解码器则将这个潜在表示解压还原。Stable Audio Open中的自动编码器把音频波形压缩成一个较短的序列,以便后续处理。
T5(Text-to-Text Transfer Transformer)是一个由谷歌开发的自然语言处理模型,它可以将输入的文本转换为另一种文本表示。在Stable Audio Open中,T5模型将用户输入的文本转换成文本嵌入(text embedding),以便于将文本信息融入到音频生成过程中。
DiT(Diffusion Transformer)是一种扩散模型,在自动编码器的潜在空间中运行,对编码器压缩后的数据进行处理和优化,确保解码器能还原出连贯、高质量的音频。

作为Stable Audio 2的变体模型,Stable Audio Open在训练数据的采用和部分架构上进行了调整。采取了完全不同的数据集,并且使用T5代替了CLAP(Contrastive Language-Audio Pretraining)。前者由谷歌开发,专注于文本数据,完成各种自然语言处理任务,而后者由OpenAI研发,即可处理语言数据,也可处理音频数据。
作为一个开源免费的模型,Stable Audio Open无法生成连贯完整的曲目,也不会针对完整的曲目、旋律或人声进行优化。
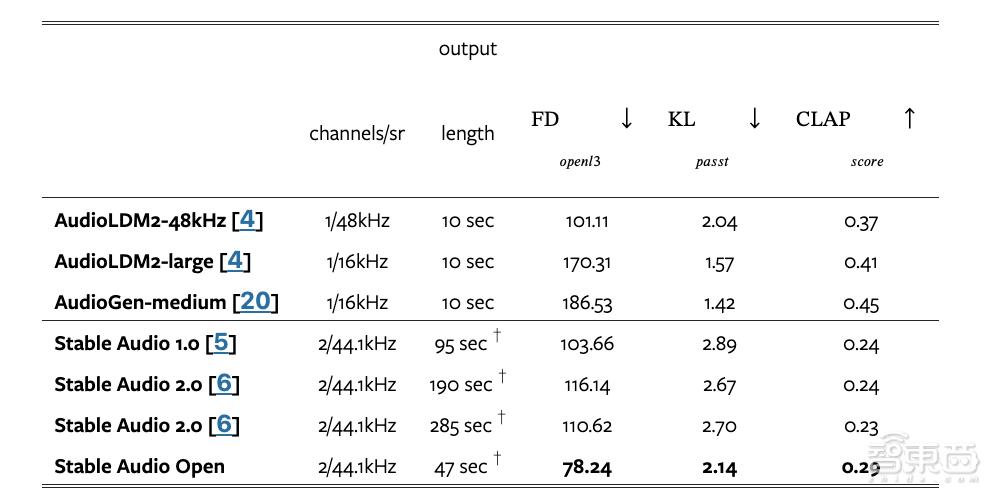
Stability AI称,Stable Audio Open专注于音频demo和音效制作,可免费生成最长47秒的44.1kHz高质量立体声音频。经过专业训练后,该模型非常适合创建鼓点、乐器重复乐段、环境音、拟音录音和其他用于音乐制作和声音设计的音频样本。
此次开源版本还有一个关键优势,即用户可以根据自己的自定义音频数据对模型进行微调,这样,用户就可以用自己的鼓声录音来训练模型,用自己的风格生成独特的节奏。
二、训练过程着重保护版权
在生成式AI快速发展的背景下,人们对音乐行业使用人工智能的争论日益激烈,特别是在版权问题上。Stability AI前音频副总裁Ed Newton-Rex于2023年底离职,理由是他不同意Stability AI在训练模型时使用受版权保护的音频,认为此举存违背伦理道德。他曾参与开发Stable Audio。
生成式AI的数据训练像是一个黑箱里进行,除了开发商,谁也不知道训练所使用的数据是否受版权保护。Newton-Rex说:“许多价值数十亿美元的科技公司在未经许可的情况下,利用创作者的作品训练生成式人工智能模型,然后使用这些模型生成新内容。”他在一封公开辞职信中表示,他不接受这种依靠侵犯创作者版权而牟利的行为。
Stability AI表示,为尊重创作者版权,Stable Audio Open使用的数据集来自Freesound和免费音乐档案(FMA),所有使用的录音均是CC(Creative Commons)许可下发布的音频录音。
CC是一种版权许可机制,该机制允许创作者共享他们的作品,并规定他人如何使用这些作品。

为了确保避免使用任何受版权保护的材料,Stability AI称通过使用音频标记器识别Freesound中的音乐样本,并将识别出的样本被发送到Audible Magic的内容检测公司,以确保从数据集中删除潜在的受版权保护的音乐。
Stability AI表示:“这让我们能够创建一个开放的音频模型,同时又能充分尊重创作者的权利。”
结语:开源、免费模型让文生音频更普及
Stable Audio Open的推出展示了Stability AI在文本转音频模型领域的创新和进步。虽然该模型在生成音频长度和连贯性上存在一定的限制,但其优点也显而易见。它能免费生成高质量的44.1kHz立体声音频,并且能在消费级GPU上运行,降低了文生音频的使用门槛。
同时,Stable Audio Open在开放音频生成技术的同时,也为版权保护树立了新标杆。在今后,随着技术的不断进步和道德规范的完善,Stable Audio Open有望在更多应用场景中发挥其潜力,推动音频生成技术的发展和普及。
目前,Stable Audio Open模型权重可在机器学习模型平台Hugging Face上获取。Stability AI鼓励声音设计师、音乐家、开发人员以及任何对音频感兴趣的人探索该模型的功能并提供反馈。
本文来自微信公众号“智东西”,作者:孟强
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则