- 行业先锋
- 文章详情

全行业卷低价的火,烧到了新生的大模型行业。
去年这时候,我们在看的是哪家企业又推出自己的大模型,性能达到或者接近GPT-4的水准;一年之后,想明白的企业已经启动了大规模的降价,集体将行业推进到中国式商战的终极阶段——价格战。
率先开启降价的是一家创业公司,名叫深度求索(DeepSeek),5月6号,他们宣布旗下开源第二代MoE大模型DeepSeek-V2标价百万tokens只需1元,定价为GPT-4-Turbo的近1%。
再之后,降价之潮快速扩张,迅速将大模型的竞争阶段从“入围赛”推进到了“淘汰赛”,其中不乏中国大模型领域的巨头企业们。字节跳动宣布豆包Pro 32k模型降价至0.8厘/千tokens;阿里云宣布通义千问9款模型一起降价,其中主力模型Qwen-Long直降97%。
有打折到骨折的,就有大户直接搞免费。百度智能云宣布文心大模型的两大主力模型ERNIE Speed和ERNIE Lite免费;腾讯云除了自家主力模型混元-lite全面免费之外,其他模型价格降幅最高达到了87.5%;科大讯飞则表示轻量级模型API永久免费……
在这个各行各业都拼低价的年代,就算是看上去最先进、最有科技含量的“大模型”也不能免俗。从一种角度看这是好事,意味着过去一年在大模型的研发过程中,这些企业都有了实打实的进展,也都有意愿加速大模型在市场中应用的进程。
但从另一个方面看,在市场上跟人打价格战,不说最后能不能赢下来,怎么才能覆盖开发大模型的研发成本和建设算力基础设施的资本开支?
01 醉翁之意不在酒
其实大家大可不必因为进入价格战而对于大模型这个行业产生怀疑,更不用看到价格战就开始心灰意冷。任何一个新技术带来的新行业,对其未来成长性的判断标准之一,就是它能否实现成本的快速下降。
这一点,无论中外,都是这样。在这一轮的大模型降价阵营中,OpenAI也是主力军之一,2023年全年,GPT3.5和4.0总计降价三次,2024年5月GPT-4o相比GPT-turbo再降价50%,百万token的处理成本降至 7 美元,虽然相比中国同行们的大模型还要贵一些,但其降幅已经相当明显了。
此外,按照OpenAI的预期,其大模型将以每年50%-75%的幅度继续下调,用不了几年就能降到白菜价。而越来越趋近于免费、甚至直接免费,将有很大概率成为大模型未来的发展趋势,从这个角度看,目前国内燃起的所谓价格战,只不过是将行业的正常趋势稍微提前一些。
当然,对于一个投资者来说,在它背后一个更关键的问题是,大模型本身越来越便宜甚至免费,那到底要靠什么挣钱?看来看去,对于目前主流的大型公司来说,答案其实只有一个:云服务。
和新生的大模型相比,云服务算得上是“老家伙”。从国外的大型企业看,亚马逊推出云服务AWS的时间是2006年6月,距今已经有18个年头;而阿里巴巴推出阿里云的时间也并不晚,只在两年之后的2008年。自那时开始,云服务开始在中大型企业中逐步推开,成为企业在数字化时代重要的基础设施之一。
简单来说,云服务是通过互联网更好地调用、扩展和管理计算及存储资源,而对于企业来说,无需在本地构筑服务器等基础设施,相当于节省了企业的IT部署成本。而从另外一方面,企业选择一家云服务,其实就意味着选择了一个生态,意味着从存储到实施,日后的开发和维护基本都会与它深度绑定,迁移成本极高。
但一个现实问题是,中国云服务企业的业务开展和业绩情况,远不如大海对岸的同行。
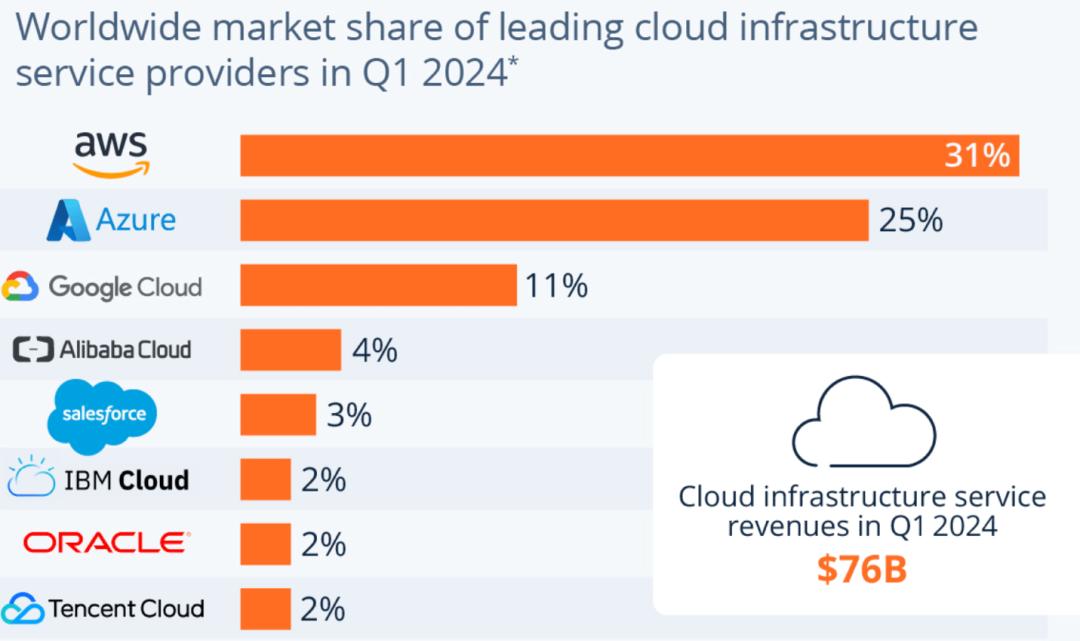
例如,亚马逊云服务(AWS)已经是全球非亚太地区市场占有率最高的云服务企业,长年市占率维持在32%至35%;而AWS也是亚马逊整个公司中利润贡献最大的业务板块,今年第一季度,AWS对公司的收入贡献只有17%,但其经营利润达到94亿美元,占比为61.4%。
国内这边,同样以市占率最高(也是数据披露相对更全)的阿里云举例,一季度其收入256亿元,同比增长3%,经调整EBITA为14.3亿元,同比增长45%,经调EBITA率只有5.6%。无论是从收入增长还是利润贡献的角度看,都远远比不上亚马逊。
当然,亚马逊算是一个特例,由于发展早、基础好、客户迁移的难度更大等原因,即便和微软、谷歌等美国巨头相比,AWS的盈利能力也是遥遥领先的。但是,自从大模型横空出世之后,AWS和拥有OpenAI的微软之间,在云服务市场中的占有率差距开始迅速缩小。
根据Statista的数据,2024年第一季度,独家拥有OpenAI服务的微软云业务Azure,在全球的市占率达到25%,高于2022年的平均市占率21%,排名全球第二;AWS的市占率则为31%,虽然还是全球第一,但这个比例低于AWS长期32%至34%的市占率区间,在与微软的竞争中显现出萎缩的态势。
独霸全球市场的AWS被微软撬出一道裂缝,想都不用想,就是因为大模型的出现。一季度,微软Azure的收入增速高达31%,高于谷歌云的28%,也高于AWS的17%,与后两者之间的增速比例拉开差距,其实就是来自大模型的加持。
看到了国外市场正在发生的变化,其实也就不难理解为什么国内这些大厂纷纷开启降价:想用便宜的大模型吗?那就连我的云服务一块用了吧。
02 增长循环
很对人会把云服务与半导体等同,视作大模型这个金矿的“铲子和镐”,但二者的逻辑完全不一样。
相对于云服务,半导体归类为“卖铲人”更贴切一些,AI计算加速芯片,是构建大模型算力的物理基础设施,算的上一个配件的角色;但云服务,和大模型更接近于“配套设施”,从实际的场景看,往往是搭配销售的。
这在商业上的体现,就是重点大模型的供应商,其实就是云服务的供应商。在国外有微软、谷歌,大模型就是他们云服务的一个主要卖点之一;在国内,这个倾向则更为明显,阿里巴巴、百度、腾讯和字节跳动等等,都有“搭售”这样的行为。
面对这样的市场状态,猎豹移动的创始人傅盛就有一段精准的叙述:
“从目前的‘战况’来看,降价最凶的都是自己有云服务的大厂,他们通过大模型来获取云客户,‘羊毛出在猪身上,降得起’;但创企没有这样的生态,必须另寻商业模式。”
以低价甚至免费当做“噱头”,推动企业特别是中小型企业上云,并在此基础之上开发自己的AI应用。这些大厂通过向企业出售云服务的诸如计算、存储等等功能获取收益,又能推动开发者用自己的大模型开发应用,甚至还能拿到宝贵且优质的数据资源,反哺大模型本身的研发和更新。
而对于国内的云服务企业来说,他们实在是太有提升自己相关业务的动力了。
弗若斯特沙利文的数据显示,与美国云服务市场相比,中国市场仍处于相对早期阶段,云服务渗透率相对较低。在2021年,互联网企业的云服务渗透率已达到93.5%,中国非互联网企业的云服务渗透率仅为26.8%。而在过去两年,中国主要云服务大厂的增长率都不如人意,非互联网企业的云服务渗透率依然处于较低水平。
大模型本身带来的一个优势,就是智能和数据的解耦。大模型的本质是智能的大规模集中供给,是智能本身的基础设施化,对于那些本身并没有大数据的企业而言,通过大模型就可以接入高质量的智能。在这里举一个简单的例子,即便是没有任何数据作为AI基础的个人用户,也可以通过AI大模型生成他想要的内容,所付出的只不过是几个提示词而已。
而在之前的时代,企业想要实现产品的智能化,就必须依靠大数据,这些数据要么从用户那里收集,要么就从自己的生产流程中生成。一个典型的例子就是抖音,它可以大量掌握用户的浏览行为数据,去推荐更精彩和更好看的短视频,让用户在自己的应用上花费更多的时间。
因此,没有大数据也可以智能化,就是大模型给商业带来的一个新的价值点,而这一切的指向目标就是中小企业。不需要大数据,意味着企业不需要有非常高的数字化基础;另一方面,在开发应用时,诸多阻碍大中型企业采纳生成式AI的因素(如数据泄密)可能对小微企业影响甚微。
于是,在看到大模型真正的应用蓝海之后,无论是大型还是小型大模型企业都选择大幅度降价也不足为奇了。这些中小企业原本的数字化程度就不高,价格敏感度却更大,降价就是吸引这些企业使用大模型最好的宣传。
但是,能否通过降价助推公司云服务的推广,达到像微软这样挑战巨头AWS市占率的好效果,这个还是未知。一方面,大模型除了聊天对话之外,还没诞生出企业级的杀手级应用,在企业的使用动力方面显得略有不足;另一方面,如今的经济环境下,中小企业能有多高的支付能力也是未知数,拉动云服务销量很难在短期见到明显效果。
除了这些大厂之外,还有个方向是找差异化路线。比如科大讯飞突出的“纯国产”、猎豹移动突出的“小参数大模型”,商汤大模型的“大装置&大模型”等等,分别切入企业的数据安全需求、低成本部署需求和全栈式解决方案需求,有在细分市场中爆发的机会,甚至可以更快见到业绩上的改变。
以商汤为例,2023年总收入34亿元,核心业务生成式AI收入增长200%达12亿元,占集团总收入比例升至35%。当然,围绕生成式AI收入具体依靠哪些业务子版块,公司的财报并未详细披露,不过根据公告,绝大部分来自于客户对大模型的训练、微调和推理收入,涉及到应用商业化方面只是刚刚开始。
至于能否看到这些大小企业之间竞争格局的改变,那就要等到大模型在应用中真正进化出前所未有的能力来,希望这个时间不会太久太远。
声明:本文仅用于学习和交流,不构成投资建议。
本文来自微信公众号“躺平指数”(ID:moneymakingsecrets),作者:躺姐
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则