- 行业先锋
- 文章详情

如火如荼的AI竞争中,「算力之战」同样热火朝天。
包括但不限于OpenAI、微软、xAI和Meta在内的多个头部公司都在争相建立超过10万卡的GPU集群,在这个规模上,仅仅是服务器的成本就超过40亿美元,还要受到数据中心容量和电力不足等多项因素的限制。
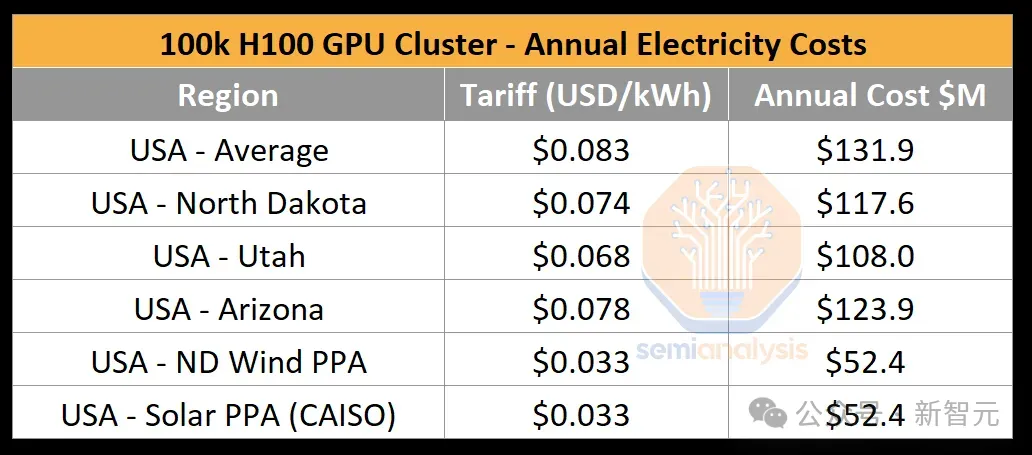
我们可以做一个简单的估算,一个10万卡集群每年耗电量约为1.59太瓦时(terawatt·h,即10e9千瓦时),按照美国电力的标准费率0.78美元/千瓦时,每年的用电成本就达到了1.24亿美元。
为了说明10万个GPU集群的强大计算能力,OpenAI在训练GPT-4时使用了大约2.15e25 BF16 FLOP(21.5百万亿ExaFLOP),在大约2万个A100上进行了90到100天的训练,峰值吞吐量只有6.28 ExaFLOPS。
若使用10万个H100代替A100,峰值将飙升至198/99 FP8/FP16 ExaFLOPS,增加了31.5倍。
在H100上,AI实验室在训练万亿参数模型时,FP8模型FLOP利用率(MFU)最高可达35%,FP16 MFU则为40%。
MFU全称为model full utilization,是衡量潜在FLOP的有效吞吐量和利用率峰值的指标,考虑了功率限制、通信不稳定、重新计算、滞后和低效内核等各种瓶颈。
使用FP8,一个10万卡H100的集群只需4天就能训练GPT-4。如果进行100天的训练,你可以实现大约6e26(600百万亿ExaFLOP)的有效FP8 FLOP。不过,硬件的低可靠性会显著降低MFU。

很多人认为,AI的三大基础设施:数据、算法、算力中,门槛最低的就是算力。只要有钱有资源,买到足够多的芯片,算力短缺就不是问题。
但是,SemiAnalysis最近的一篇文章指出,事实绝非如此。构建算力集群,绝对比一掷千金要复杂得多。
GPT-4发布以来,似乎还没有出现下一代能力更强的LLM,很重要的原因就是几乎没有组织能够大规模增加专用于单个模型的计算量。
Gemini Ultra、Nemotron 340B和Llama 3这些模型与GPT-4的训练计算量相近(约为2e25 FLOP),甚至更高,但使用了较差的集群架构,导致它们无法进一步释放能力。

那么,在巨头们部署10万卡GPU集群的过程中,究竟面临哪些障碍?
电力挑战
10万卡集群所需的关键IT部件的总功率约为150MW,相比之下,美国最大的国家实验室超算El Capitan的关键IT功率只有30MW,约为五分之一,可谓是相形见绌。
在如此庞大的功率中,GPU本身的耗电实际上只有不到一半。
根据官方参数,每张H100的功率为700W,但服务器上还有CPU、网卡(NIC)、供电单元(power supply unit)等设备,功率约为575W。
除了H100服务器,集群中还需要部署一系列的存储服务器、网络交换机、CPU节点、光纤收发器和许多其他设备,约占IT功耗的10%。
目前没有任何一座数据中心的大楼有能力部署150MW功率的设备。因此,已建成的10万GPU集群通常是分布在一整个园区中,而非单座大楼。
由于可用的数据中心有限,xAI甚至选择将田纳西州孟菲斯的一家旧工厂改造为数据中心。
因为服务器分布在整个园区而非单栋大楼内,联网成本就会无形增高,因为光纤收发器的成本与传输距离成正比。
「多模」SR和AOC收发器仅支持最长约50m的传输距离,显然不可用。长距离「单模」DR和FR收发器能可靠地在500m~2km范围内传输信号,但成本是前者的2.5倍。
此外,园区级别的800相干光收发器的传输距离可以超过2km,但价格更贵,要高出10倍以上。

H100的小型集群通常只使用多模收发器,通过一层或两层的交换机,以400G的速度将每个GPU连接在一起。如果是大型集群,则需要增加更多层的交换机,光纤设备也会极其昂贵。
在大型集群的园区中,每栋大楼包含一个或多个pod,由多模收发器(或者较为廉价的铜缆)相连,形成一个「计算岛」。每个计算岛之间再通过长距离收发器互连,岛内带宽较高,岛间带宽较低。

并行化方案
数据并行
在较大参数的训练中,一般有3种不同类型的并行化——数据并行(data parallelism)、张量并行(tensor parallelism)与流水线并行(pipeline parallelism)。
数据并行是其中最简单的并行方式:每个GPU拥有模型权重的全部副本,并分别保存一部分数据。
前向计算过程中每个GPU独自工作,梯度更新时将所有GPU计算出的梯度相加,再一起更新,因此在三种方式中,数据并行对GPU间通信的要求最低。
然而,这种方案要求每个GPU都有足够内存来存储整个模型的权重、激活函数和优化器状态。像GPT-4这种级别的LLM,参数规模可以达到1.8万亿,需要占据10.8TB内存,显然无法全部塞到一个GPU中。

张量并行
为了克服内存的限制,就有人提出了张量并行:神经网络中每一层的权重和计算都分布在多个GPU上,一般会覆盖全部隐藏层。在每一层的自注意力、前馈网络和层归一化等操作中,都需要设备间进行多次归约。
可以想象成,在每一层的前向计算中,所有GPU都在协同工作,仿佛组成了一个巨型GPU。
目前在NVLink上通常使用8个张量并行等级,相当于每个GPU的内存消耗降低到了原来的八分之一。
由于这种方式中设备间需要频繁通信,因此要求高带宽、低延迟的网络环境。

流水线并行
除了张量并行,GPU内存不足的另一种解决方案就是流水线并行。
顾名思义,这种方案是将前向计算看成一个流水线,每个GPU负责其中一环,也就是网络中的一层或几层,完成计算后将结果传递给下一个GPU。
流水线并行对跨设备通信的要求也很高,但没有张量并行那么苛刻。

为了最大限度地提高模型FLOP利用率,三种并行模式通常结合使用,形成3D并行。
张量并行对通信要求最高,因此应用于同一服务器内的多个GPU, 再在同一计算岛内的节点间使用管道并行。
由于数据并行的通信量最小,而且岛与岛之间的联网速度较慢,因此跨计算岛时使用数据并行。

网络设计
拓扑结构
进行网络拓扑设计时需要同时考虑到所用的并行化方案。
如果采用胖树拓扑结构(fat-tree topology),每两个GPU之间都用最大带宽相连,就需要4层交换,成本十分高昂。

论文《Adaptive Load Balancing Scheme For Data Center Networks Using Software Defined Network》
因此,没有大型GPU集群会部署全胖树架构。取而代之的方案是,制造具有全胖树架构的计算岛,同时减少岛间的带宽。
比如,Meta的上一代GPU集群架构使用了3.2万张芯片,总共有8个计算岛,岛与岛之间部署全速带宽,然后在顶部另加一个7:1的收敛比(oversubscription)的交换层,于是岛与岛之间的联网速度就是岛内的七分之一。

网络设备部署
GPU部署有多种网络,包括前端网络、后端网络和扩展网络(NVLink),每个网络中运行不同的并行方案。
对于张量并行的带宽要求而言, NVLink网络可能是唯一足够快的网络。后端网络通常可以轻松处理大多数其他类型的并行,但如果存在「收敛比」,通常只能采用数据并行。
此外,有些数据中心甚至没有在顶层设置「收敛比」带宽的孤岛。相反,他们将后端网络迁移到前端网络。
一家大型公司利用前端以太网在多个InfiniBand计算岛上进行训练。这是因为前端联网的成本要低得多,而且可以利用楼宇间现有的数据中心园区网络和区域路由。

遗憾的是,由于采用了MoE等稀疏技术,模型尺寸增长速度加快,前端网络需要处理的通信量也随之增加。
这种权衡必须仔细优化,否则最终会出现两种方案网络成本趋同的情况,因为前端网络带宽最终会增长到与后端网络带宽相匹配的程度。
值得注意的是,谷歌在多TPU pod训练运行中只使用前端网络。他们被称为ICI的「计算结构」最多只能扩展到8960个芯片,每个包含64个TPU的水冷机架之间需要使用昂贵的800G光纤和光路交换机进行连接。
因此,谷歌必须使TPU前端网络比大多数GPU前端网络更强大,以弥补这一不足。

在训练过程中使用前端网络时,全局归约操作必须能够依据各计算岛之间的网络拓扑结构。
首先,每个pod或计算岛将在内部的InfiniBand或ICI网络中执行局部的规约-分散操作,使每个GPU/TPU拥有梯度的一部分总和。
接下来,将使用前端以太网络在每个主机等级之间执行跨pod归约,最后每个pod将执行pod级全收集。
前端网络还负责加载数据。随着多模态图像和视频训练数据的发展,对前端网络的要求将呈指数级增长。
在这种情况下,加载大型视频文件和归约这两种操作之间将争夺前端网络带宽。
此外,由于存储网络流量不规则,会导致整个归约过程变慢,无法进行预测建模,从而增加了滞后问题。
另一种方法是使用4层InfiniBand网络, 采用 7:1的收敛比,4个pod, 每个pod有24576个H100,采用无阻塞3层系统。
与使用前端网络相比,这为将来增加带宽提供了更大的灵活性,因为与升级集群中每个机箱的前端网络网卡相比,在两个大楼的交换机之间添加更多光纤收发器要容易得多。

这样可以创建一个更稳定的网络模式,因为前端网络可以只专注于加载数据和检查点,而后端网络可以只专注于GPU间通信。但遗憾的是,由于需要额外的交换机和收发器,4层Infiniband网络非常昂贵。
轨道优化与中间架
为了提高可维护性并增加铜缆网络(<3米)和多模网络(<50米)的使用,一些客户选择放弃英伟达推荐的轨道优化设计(rail optimized design),转而采用中间架设计(Middle of Rack design)。

轨道优化是一种技术,可让每台H100服务器连接到8个不同的叶交换机(而不是全部连接到同一个机架中的交换机),这样每个GPU只需跳一次交换机就能与更远的GPU通信,提高全对全集体通信(all-to-all collective communication)性能。
比如在混合专家(MoE)并行中,就大量使用了全对全集体通信。

轨道优化设计的缺点则是,必须连接到不同距离的不同叶交换机,而不是将一个机架中间的交换机靠近服务器中的所有8个GPU。
当交换机位于同一机架时,可以使用无源直连电缆(DAC)和有源电缆(AEC),但在轨道优化设计中,交换机不一定位于同一机架,因此必须使用光学器件。
此外,叶交换机到骨架交换机的距离可能大于50米,因此必须使用单模光收发器。
如果采用非轨道优化设计,则可以用廉价的直连铜缆取代连接GPU和叶交换机的98304个光纤收发器,从而使您 GPU链路中铜缆占比达到 25-33% 。
从下面的机架图中可以看到,每个GPU与板上交换机的连接不再是先连接到电缆托架,然后再从侧面穿过9个机架连接到专用的轨道优化板上的交换机机架,而是将板上交换机放在机架中间,让每个GPU都能使用DAC铜缆。

与光缆相比, DAC铜缆运行温度更低、耗电更少、成本更低,且可靠性更高,因此这种设计就减少了网络链路间歇性瘫痪和故障,而这正是所有使用光学器件的高速互连所面临的主要问题。
在使用DAC铜缆时,Quantum-2IB骨架交换机的耗电量为747瓦。使用多模光纤收发器时,功耗会增加到1500瓦。

此外,轨道优化设计的初始布线对于数据中心技术人员来说非常耗时,因为每个链路的两端距离长达50米,而且不在同一个机架上。
而在中间机架设计中,叶交换机与连接到叶交换机的所有GPU位于同一机架上,甚至设计完成之前,可以在集成工厂测试计算节点到叶交换机的链路,因为所有链路都在同一个机架上。

可靠性与恢复
由于当前的模型训练都是同步进行,可靠性就成为了巨型集群最重要的运行问题之一。最常见的可靠性问题包括GPU HBM ECC错误、GPU驱动器卡死、光纤收发器故障、网卡过热等。
为了保持较短的平均故障恢复时间,数据中心必须在现场保留热备用节点和冷备用组件。发生故障时,最好的办法不是直接停止训练,而是换上已经开启的备用节点继续训练。
事实上,大部分服务器宕机的情况都可以通过重启修复,但有些时候则需要技术人员对设备进行现场诊断和更换。
在最好的情况下,数据中心技术人员只需几个小时就能修复损坏的GPU服务器,但很多情况下,损坏的节点可能需要几天时间才能重新投入使用。
在训练模型时,需要经常将检查点存储到到CPU内存或NAND SSD, 以防出现HBM ECC等错误。发生错误时,必须重新加载模型和优化器的权重,再继续训练。
容错训练技术(如Oobleck))可用于提供用户级应用驱动方法,以处理GPU和网络故障。
遗憾的是,频繁地备份检查点和容错训练技术会损害系统的整体MFU,因为集群需要不断暂停,将当前权重保存到持久内存或CPU内存中。
此外,通常每100次迭代才保存一次检查点,这意味着每次重新加载时你最多会丢失99步有用的工作。在一个10万卡集群上,如果每次迭代耗时2秒,那么在第99次迭代失败时,最多会损失229个GPU日的工作。
故障恢复的另一种方法是让备用节点通过后端结构从其他GPU进行 RDMA复制。后端GPU的速度约为400Gbps, 每个 GPU有80GB的HBM内存,因此复制权重大约需要1.6秒。
采用这种方法,最多只能损失1个步骤(因为更多GPU HBM将拥有最新的权重副本),因此只需2.3个GPU日的计算时间,再加上从其他GPU HBM内存RDMA复制权重的1.85个GPU日。
大多数领先的人工智能实验室都采用了这一技术,但许多小型公司仍坚持使用繁重、缓慢、低效的技术,即从检查点重新启动处理所有故障。通过内存重构实现故障恢复可为大型训练运行的MFU提升好几个百分点。

网络故障方面,最常见问题之一是Infiniband/RoCE链路故障。由于收发器数量较多,即使每个网卡到最底层交换机链路的平均故障率为5年,在一个全新的、正常运行的集群上发生第一次作业故障也只需要26.28分钟。
如果不通过内存重建进行故障恢复,那么在10万卡的GPU集群中,由于光纤故障而重新启动运行所花费的时间,将比模型实质进行计算所花费的时间更多。

由于每个GPU都直接连接到ConnectX-7网卡(通过PCIe交换机),在网络架构层面没有容错能力,因此故障必须在用户训练代码中处理,增加了代码库的复杂性。
这是当前英伟达和AMD的GPU网络结构的主要挑战之一,即使一个网卡故障,该GPU无法与其他GPU通信。
由于大语言模型(LLM)在节点内使用张量并行,如果一个网卡、一个收发器或一个GPU故障,整个服务器就会宕机。
目前有很多工作正在进行,以使网络可重配置,减少节点的脆弱性。这项工作至关重要,因为现状意味着整个GB200 NVL72仅因一个GPU或光学故障就会宕机。
显然,一个价值数百万美元的72 GPU机架宕机比一个价值几十万美元的8 GPU服务器宕机更具灾难性。
英伟达已经注意到这个重大问题,并增加了一个专用的RAS(可靠性、可用性和可维护性)引擎。
其中,RAS引擎通过分析芯片级数据,如温度、恢复的ECC重试次数、时钟速度、电压等指标,来预测芯片可能的故障并提醒数据中心技术人员。
这将使技术人员能够进行主动维护,例如使用更高的风扇速度配置来保持可靠性,并在以后的维护窗口期中将服务器从运行队列中撤出进行进一步的物理检查。
此外,在开始训练任务之前,每个芯片的RAS引擎将执行全面的自检,例如运行已知结果的矩阵乘法以检测静默数据损坏(SDC)。
成本优化
Cedar-7
一些客户如微软和OpenAI正在使用Cedar Fever-7网络模块,而不是8个PCIe形式的ConnectX-7网络卡。
使用Cedar Fever模块的主要好处是,它仅需4个OSFP插槽而非8个,并允许在计算节点端使用双端口2x400G收发器。
这将每个H100节点连接到叶交换机的收发器数量从8个减少到4个;计算节点端连接GPU到叶交换机的收发器总数从98304减少到49152。

由于GPU到叶交换机的链接减少了一半,这也有助于延长首次作业失败的时间。
根据估计,每个双端口2x400G链接的平均故障时间为4年(相比单端口400G链接的5年),这将使首次作业失败的估计时间从26.28分钟延长至42.05分钟。

Spectrum-X
InfiniBand的优势在于,以太网并不支持SHARP网络内缩减。
而SHARP能将每个GPU需要进行的发送和写入次数减少2倍,因此它的理论网络带宽也增加了2倍。
但InfiniBand NDR Quantum-2交换机只有64个400G端口,而每个Spectrum-X以太网的SN5600交换机有128个400G端口,Broadcom的Tomahawk 5交换机ASIC也支持128个400G端口。
由于Quantum-2交换机的端口容量较低,在一个拥有10万节点的集群中,完全互联的GPU数量最多只能达到65,536个H100。
不过,下一代InfiniBand交换机——Quantum-X800,将通过144个800G端口解决这个问题,但从「144」这个数字可以看出,这是为NVL72和NVL36系统设计的,不太可能在B200或B100集群中广泛使用。

Spectrum-X的主要优势在于其得到了NVIDIA库如NCCL的一级支持——老黄会将你推到他们新产品线的首批客户队列中。
相比之下,如果你使用的是Tomahawk 5芯片,就需要大量的内部工程努力来优化网络以实现最大吞吐量。
然而,如果采用Spectrum-X,就必须加价购买Nvidia LinkX产品线中的收发器,因为其他收发器可能无法正常工作或者通不过英伟达的验证。
此外,英伟达在第一代400G Spectrum-X中,使用了Bluefield-3来代替ConnectX-7作为临时解决方案。(ConnectX-8预计能够与800G Spectrum-X完美配合)
在超大规模的数据中心中,Bluefield-3和ConnectX-7的价格差异约为300美元ASP,但前者要多耗电50瓦。因此,每个节点需要额外的400瓦功率,降低了整体训练服务器的「每皮焦尔智能度」。
现在,将Spectrum-X放入数据中心需要额外的5MW功率来部署10万个GPU,而使用相同网络架构的Broadcom Tomahawk 5则不需要。

Tomahawk 5
为了避免给英伟达支付高昂的费用,许多客户选择部署基于Broadcom Tomahawk 5的交换机。
每个基于Tomahawk 5的交换机与Spectrum-X SN5600交换机一样,拥有128个400G端口,如果公司有优秀的网络工程师,可以实现类似的性能。此外,你可以从任何供应商购买通用的收发器和铜缆,并进行混合使用。
大多数客户直接与ODM合作,如Celestica的交换机,以及与Innolight和Eoptolink的收发器。
基于交换机和通用收发器的成本,Tomahawk 5相比Nvidia InfiniBand便宜得多,相比Nvidia Spectrum-X也更具成本效益。
不幸的是,你需要足够的工程能力来为Tomahawk 5修补和优化NCCL通信集群。毕竟,虽然后者开箱即用,但仅针对Nvidia Spectrum-X和Nvidia InfiniBand进行了优化。
好消息是,如果你有40亿美元用于10万个集群,就应该也有足够的工程能力来修补NCCL并进行优化。
当然,软件开发是困难的,但Semianalysis认为,每个超大规模数据中心都会进行这些优化并抛弃InfiniBand。

物料清单
每10万个H100集群的总资本支出约为40亿美元,但具体金额会因所选择的网络类型而有所不同。
具体来说,可以分为四种:
1. 4层InfiniBand网络,包含32,768个GPU集群,轨道优化,7:1收敛比
2. 3层Spectrum X网络,包含32,768个GPU集群,轨道优化,7:1收敛比
3. 3层InfiniBand网络,包含24,576个GPU集群,非轨道优化,用于前端网络的集群间连接
4. 3层Broadcom Tomahawk 5以太网网络,包含32,768个GPU集群,轨道优化,7:1收敛比

可以看到,选项1比其他选项贵了1.3到1.6倍;选项2虽然提供了更大的集群、更高的集群间带宽和相似的成本,但需要更多的电力;而选项3则会严重降低并行方案的灵活性。
综上,基于Broadcom Tomahawk 5的32k集群,搭配7:1的收敛比是最具成本效益的选项,这也是多家公司选择构建类似网络的原因。
平面布局
最后,在集群的设计上,还需要优化机架布局。
从图中可以看到,有些行的叶交换机并不在同一排,这其实是为了优化使用50米多模光纤。
因为如果将多模收发器放在行的末端,中间的主干交换机将超出距离范围。

使用轨道优化的Spectrum-X / Tomahawk 5的32k集群平面图
在这个微软开发集群中,每个机架支持高达40kW的功率密度,每个机架容纳四个H100节点。

目前,这个拥有10万个节点的集群的4栋建筑中,有3栋已经建成
而从H100服务器到叶交换机的连接则使用多模AOC光纤,通过蓝色电缆识别。

展望未来,随着博通几乎主导了所有超大规模集群,他们的网络收入将继续飙升。
与此同时,由于众多新兴云服务和企业倾向于选择英伟达的参考设计,这家巨头在网络方面也将继续增长。
参考资料:
https://www.semianalysis.com/p/100000-h100-clusters-power-network
文章来自于微信公众号“新智元”,作者 “乔杨,好困”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则