- 行业先锋
- 文章详情

OpenAI在5月14日推出了新一代人工智能模型GPT-4o,支持文本、音频和图像的任意组合输入,并能够生成文本、音频和图像的任意组合输出。仅仅一天后,谷歌就在新一届I/O开发者大会上发布、更新了十多款产品,包括AI助手Project Astra、文生图模型Imagen3、对标Sora的文生视频模型Veo,以及备受瞩目的大模型Gemini 1.5 Pro的升级版。
从2023年初开始,我们见证了人工智能有一轮前所未有的爆发式成长。在这波浪潮中,也产生了很多思考和疑问——为什么沉寂多年后,人工智能会在2023年开始大爆发?新一代人工智能是如何炼成的?有前景的商业应用有哪些?大模型对社会、企业和个人会产生什么影响?人类的工作是否会被替代?未来的生产模式和商业模式又是什么样的?
一、爆发之前:大模型是如何成功的?
1. 机器学习
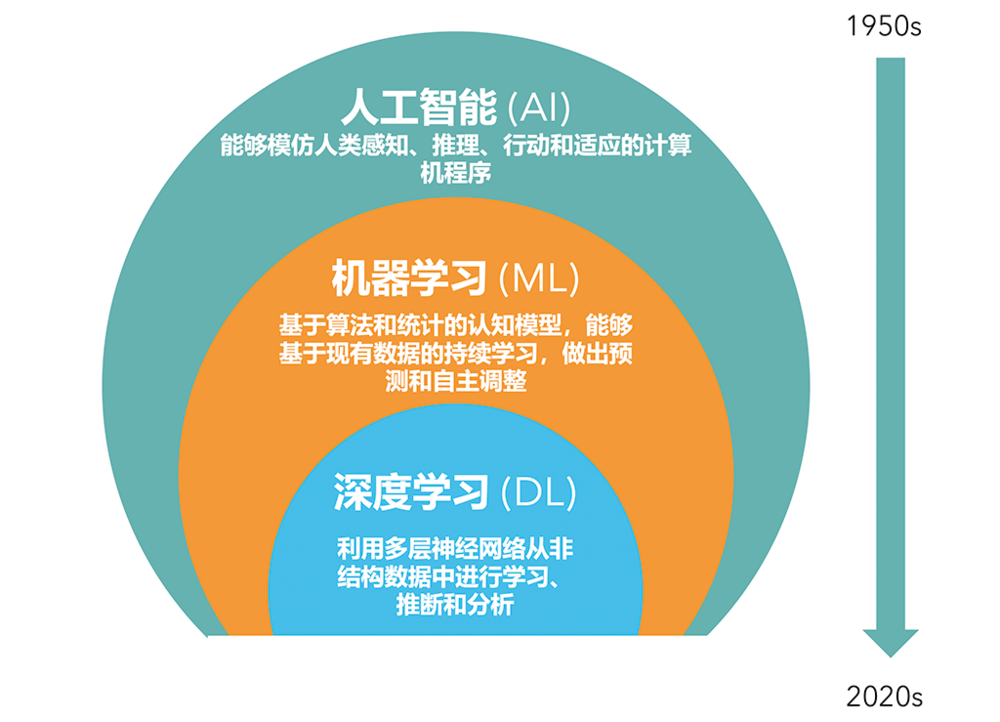
早在上个世纪50年代,人工智能就有了非常成熟的基础定义,即能够模仿人类感知、推理、行动和适应的计算机程序。那是在1956年的达特茅斯会议(人工智能的创始会议)上被提出的。我们今天看到的人工智能,是这个大概念下的一个子集,叫机器学习,它是基于算法和统计的认知模型,通过对现有数据的持续学习,做出预测和自主调整。
机器学习已经广泛应用于企业中。例如,一家物流公司派发120个包裹,如何规划最优路线?在没有人工智能辅助的情况下,路线很可能是司机一拍脑袋决定的,通常并非最优解。而机器学习能帮助企业打破这种局限,它通过算法研究司机走过的路线,并把时段、路况、天气等因素都考虑在内,从中发现规律,得出超乎意料的高效路线。
UPS从2003年开始研究如何用人工智能去优化包裹投递路径,每年为企业节省了3~4亿美元的成本、1亿英里的路程、1000万加仑的油耗,以及10万吨温室气体排放。这就是机器学习的早期应用——通过对各种数据、特征的提取,在企业内部实现降本增效。另一类应用则是通过外置资源的调配创造新的平台经济,抖音、美团、滴滴等平台都是由机器学习的算法驱动的,并且都实现了指数级增长。
2. 深度学习
机器学习的算法基础,是结构性数据,即能放进Excel表格的信息,如性别、日期、距离等。但在这个世界上,不仅有结构性数据,还有非结构数据。文字、图像、视频,人们的所见所闻、所思所想,都是非结构性数据。如果我们把它们抽象为结构性数据,就会导致信息损失。人类没有办法通过结构性数据去捕捉大千世界纷繁复杂的信息,由此衍生出了深度学习的概念。
今天如日中天的人工智能应用,如大模型、Sora、自动驾驶等,都属于深度学习范畴。所谓深度学习,就是利用多层神经网络从非结构性数据中进行学习、推断和分析,最初也叫卷积神经网络。从1989年卷积神经网络算法LeNet诞生,到1998年成功实现商业化,历时近十年,但也只是被金融和邮政机构用来读取信件或支票上的数字与条码。
这样普适性的技术,为什么在当时应用如此狭窄?因为深度学习需要满足两个严苛的条件:一是算力,它需要进行大量计算,非常消耗算力,当时的计算机性能还没办法支撑;二是数据,它需要大量的非结构数据进行训练,而当时还没有人对非结构性数据进行系统性收集。
2006年,英伟达开始通过GPU和GPU上面的一系列软件构架对算法进行了突破,现在英伟达的市值已超过2万亿美元。缺乏训练数据的瓶颈则是由华裔科学家李飞飞带领团队突破的。2007年,李飞飞在美国的零工平台MTurk雇用了很多零工去做数据的清洗、标记和下载,历时3年多,来自167个国家的5万人参与了10亿张备选图片的标注,最终做出了ImageNet数据库。这是深度学习实现技术突破的重大标志性事件。
2010年,李飞飞开始举办ImageNet大规模视觉识别挑战赛。2012年,谷歌团队在参赛时用了一个新技术——卷积神经网络AlexNet,将图像识别的错误率降到了15.3%,到2014年又降到了5%。通过这项比赛,人类达成了在视觉识别上让计算机超过自己的目的。
现在,视觉识别已被广泛应用在企业内部,以及市场拓展和营销中。比如,沃尔玛通过视觉识别技术去分析产品是否需要及时补货,让整个运营和物流保持高效;顺丰也通过视觉识别去查看包裹有没有破损、员工有没有暴力分拣。
李飞飞是通过散落在世界各地的零工去做数据标记的,因此才有了数据库和数据产业的诞生。这不仅是技术的创新,也是组织模式的创新。现在,由于经济的波动和变化,我们十分担心就业问题,事实上从2010年起,零工经济、众包形式就已开始出现,劳动力市场正在发生深刻变化,而这种变化是和技术跃迁紧密相连的。
3. DeepMind
围棋是棋界的珠穆朗玛峰,两人对弈时,棋路变幻莫测。当年DeepMind想研究人工智能下围棋,大家都认为是天方夜谭。但在2016年,DeepMind开发的AlphaGo以4:1的成绩战胜了李世石,引起极大轰动。之后AlphaGo迅速迭代,两年间学完了人类所有的棋谱,然后开始自己和自己对弈,发展成了非常强大的算法。
卷积神经网络的另一个重大应用,是预测蛋白质的原子级精度结构。DeepMind用AlphaFold在两年内预测了58%的人类蛋白质结构,而人类用50年只做了17%的蛋白质解析。2022年,AlphaFold已预测出超过100万个物种的2.14亿个蛋白质结构,几乎涵盖了地球上所有已知蛋白质。
可以看出,在七八年前,人工智能卷积神经网络首先替代的不是蓝领、白领的工作,而是科学家的工作。科学家用50年积攒的智慧,人工智能两三年就完全突破了,但科学家们并没有因此感到沮丧。事实上,这个蛋白质数据库大幅增加了科学家在开发新药时所拥有的选项,让他们可以不局限于蛋白质解析工作,而更专注于拓展药物研发,去攻克那些真正关键的难题。
4. 注意力机制
为什么深度学习可以打败李世石,可以解析复杂的蛋白质结构,但在很长时间内却解析不了人类的语言?因为语言是高度复杂和不确定的,它是意识的反映,是连贯而有情境的。我们对于语言的理解,也是我们对于知识、环境及潜在文化的理解。
1998年,《战略管理学期刊》上发表了一篇非常重要的文章,叫《以注意力为基础的企业观》。西北大学的威廉·欧卡秀(William Ocasio)教授认为,企业的决策行为是由领导者的注意力机制决定的。公司行为是决策者注意力分配的结果,决策者关注那些问题,才会去寻找答案;而答案的搜寻则由整个公司的运行、惯例和制度来完成。这跟解决大模型语言问题的方法有异曲同工之妙。
2018年,谷歌团队在计算机领域发表了一篇类似文章《注意力就是你所需要的一切》,提出了注意力机制。众所周知,人类的注意力会自动过滤掉不重要的信息,而保留重要的信息,这就是大模型工作的原理。具体来说有几个方法——聚焦、过滤、上下文感知、关注漂移等。计算机科学家们让这些方法变成了可编程的计算机语言,使得计算机也具备了注意力机制,从而让深度学习算法大模型具有理解语言的能力。
在注意力机制下,文字、语音、图像、视频等非结构性信息之间并无太大差别。我们看到OpenAI在推出ChatGPT之后,一年内就推出了Sora视频大模型,因为二者的底层技术是相通的,不一样的只是数据。Sora之所以能生成60秒的视频,和微软强大的算力支持有关。Pika也是非常火的独角兽,却只能生成两三秒的视频,大概率是因为没有算力去支持它生成长的视频。
注意力机制技术让算力变得空前重要,只要有算力,就能让算法更完善、概率更精准、学习更高效。
二、应用之途:企业该如何入局人工智能?
1. 是局限亦是机会
大模型其实不具备我们所说的功能语言能力,它生成的文字只是字面意义,而不是对于世界的理解和认知。我们说大模型有幻觉,这非常正常,因为它做的是词义联想,即根据最大化概率去填空,不像我们人类,对于整个世界有基本的认知和假设。
这个世界的基本物理规律,大模型其实一无所知,在视频和图文方面都是如此。这是一个非常大的局限,也是一个非常大的机会。我们需要研发辅助技术去填补空白,这会产生很多技术创新的机会。
所有的大模型都更适用于合规和惯例的表达及传递,而不是用于创意和创新。它遵循的是世界上最有可能发生的事,但创新是要找到世界上还没有发生的事。我们总是担心人工智能会不会消灭人类,其实它更多是服从人类命令,至少到目前为止,它是帮助人类更好地执行一些细节性操作,而不是替代人类去做创意性工作。
2. 反向创作
我在小红书看到一个例子,是一位摄影师拿人工智能去反向创作。他让人工智能生成一个图像,借助它的光影,自己去创造一个真的摄影作品,再进行艺术创作。这是一个非常有意思的应用,人工智能被人类拿来作为灵感的源泉。

小红书上的反向创作案例。图片来源:摄影师董名扬
制作Sora Demo也相对容易,以后《复仇者联盟》中外星人入侵那样天马行空的场景,制作将不再困难,成本也不再高昂。
3. 机器人
ChatGPT不仅能生成图文、视频,还能生成代码,这也可以用到机器人上。一旦硬件成熟了,我跟机器人说,帮我去取一个快递,它就可以把自然语言翻译成机器人可执行的代码,进而完成命令。机器人产业会有非常大的发展机遇。通过内置大模型,人类以自然语言就可以直接驱动机器人。
4. 自动驾驶
自动驾驶是大模型应用非常重要的一个潜力领域。2018、2019年时,我在湾区接触了很多自动驾驶领域的计算机科学家。当时我发现自动驾驶其实是一个高人工、而不是高人工智能的行业,每张路况图片都需要非常精准的标注,具体到消防栓、红绿灯甚至马路边缘等。但有了注意力机制,无需数据标注的自动驾驶系统出现了,这可能会产生颠覆性效果。
5. 传承企业惯例
在企业内部,我们会用ChatGPT去写一些惯例性文件,如商务邮件、会议纪要、新闻通稿、招股说明书等。大语言模型是做最大概率的词义联想,所以能写出非常合规的文件。这几乎是它最基础的应用,但需要企业有一个比较高的数字化程度,企业的通信设备、数据库、规章制度,必须都进行数字化,大模型才能知道企业要什么、惯例是什么,它才能遵守。这里面的商业机会也不少。
正如1982年两位经济学家——尼尔森和温特所说的,企业最重要的竞争优势、核心能力在于企业的惯例,每个企业都有自己独特的规章制度和知识传承。这些知识往往存在于经理人、领导人的脑海中。如果通过数字化进程,把这些知识显性化喂给大模型,那么企业的知识载体就不再局限于人,还有信息系统和大模型算法。
大模型对企业知识的提取、解读、总结、归纳的能力,将会非常深刻地改变企业运行机制。未来,企业专有数据的采集和训练将是一个新的增长点,成为垂直模型和新技术演化的起点和方向。
在社会层面,大模型最基础的应用,是写一些形式主义的文稿,而且可以写得很漂亮。人类之所以要写这些文稿,其实是要表达对于社会规则的遵从。有社会学家认为,整个社会、整个行业,如果从历史纵深的角度来看,会越来越趋同,这个趋同性是社会运行的一个根本,我们会排除那些不守规则的部分。
最后一个行业也会越来越像,因为我们需要对行业制定规则,然后遵守和传承。从这个角度来看,人工智能不仅参与了企业的惯例、规则的制定和改变,还参与了社会文化的变迁。这不仅是一个信息化进程,也是人类关系构建、认知进化的进程。
文章来源于“中欧EMBA”,作者“杨蔚”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则