- 行业先锋
- 文章详情

由腾讯音乐娱乐的Lyra Lab团队开发的Muse 开源系列项目,它的最后一个模块终于来了——MusePose !发布后却真诚致谢阿里的项目?
关于Muse这个项目其实早在2023年3月就开始了,同年7月就实现了一个里程碑。但在今年开年Sore面世,让世人震惊的同时,腾讯也开始坐不住了,今年3月份立马开源了MuseV和MuseTalk两个Muse系列项目,但当时Muse开源系列其实还缺少一块重要的基石。
直到5月27号MusePose正式发布,总算是正式补齐了Muse系列数字人开源框架!
MuseV、MuseTalk协同创作
先简单给大家回顾腾讯的前两个Muse 项目:
MuseV:是一个基于扩散的虚拟人视频生成框架,进一步扩展了虚拟内容的创作边界。它能够根据文本描述生成视频,或者将静态图像和姿势转换成动态视频。
项目地址:
https://github.com/TMElyralab/MuseV?tab=readme-ov-file
MuseTalk:是一个在潜在空间中训练的实时高质量音频驱动的口型同步模型,它能够在潜在空间中对面部区域进行修改,以匹配输入的音频,支持多种语言,并实现每秒30帧以上的实时处理速度。

项目地址:https://github.com/TMElyralab/MuseTalk?tab=readme-ov-file
MuseV➕MuseTalk协同生成效果:


敲重点:MusePose是什么?
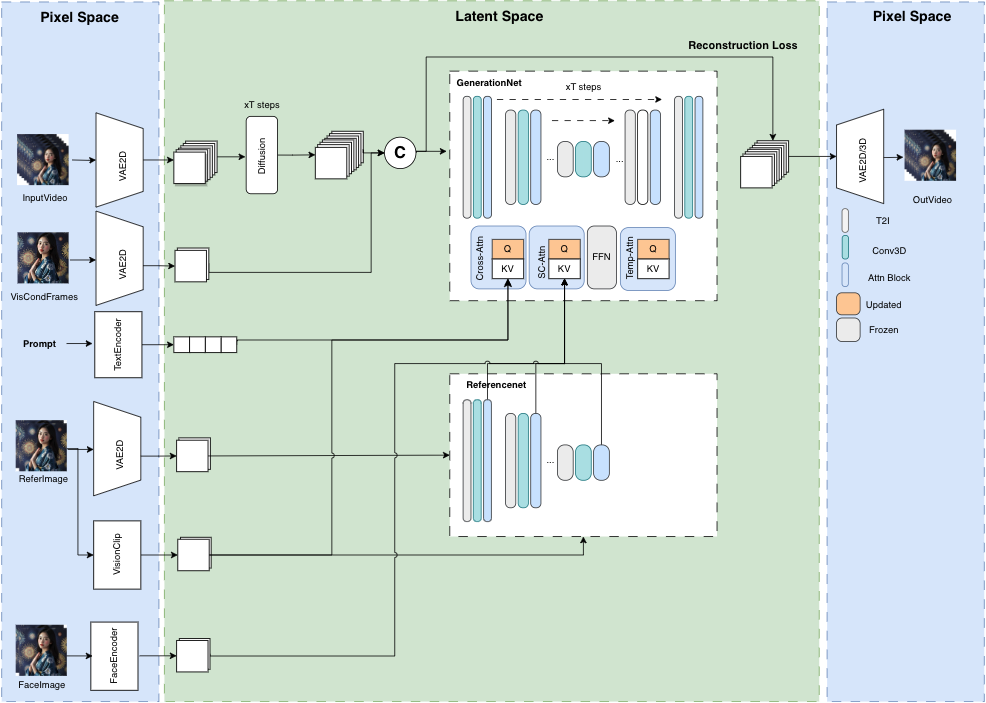
MusePose:是姿态驱动的图像到视频生成框架,专注于虚拟人类的生成,能够在给定的姿态序列下,生成参考图像中的人类角色的舞蹈视频。配合上MuseV和MuseTalk,可以实现端到端的虚拟人类生成,包括全身运动和互动能力。

MusePose和MuseV有什么区别
- MusePose和MuseV均可以完成图生视频,MuseV的视频动作随机性大,而MusePose是按给定动作生成,动作固定。
- MusePose需要12G以上显存,生成时因为占用共享显存,生成的视频清晰度和稳定性略差。
- MuseV需要8G以上显存,推荐12G以上,若图片分辨率越高、动作越小、则越稳定,生成的视频清晰度也就越高。
MusePose这个项目侧重于Pose,即姿态引导
姿态引导是 MusePose 的关键技术之一,通过给定的姿态序列,模型能够生成参考图像中的人物在这些姿态下的动画。
具体实现方式包括:
- 姿态对齐算法(Pose AIlgnment Plgorithm):该算法将任意舞蹈视频的姿态与任意参考图像对齐,确保生成的视频中的人物动作与输入姿态序列一致。
- 姿态序列生成:通过姿态对齐算法,生成参考图像人物在不同时间的姿态序列,这些姿态序列用作生成视频的输入。


MusePose Comfy UI 工作流
当前社区已有对应的ComfyUI插件支持。
插件地址为:
https://github.com/TMElyralab/Comfyui-MusePose/blob/main/musepose-workflow-demo.json
工作流展示效果如下:

Muse生态目标
MusePose、MuseV和MuseTalk三个项目,共同构建一个完整的虚拟人类生成解决方案。从动态捕捉到视觉内容的生成,再到声音与形象的完美融合,Muse系列项目旨在为虚拟人物的创建提供全方位的技术支持。
腾讯:感谢开源,感谢阿里
等等,看到腾讯Muse系列的Demo,是不是感觉似曾相识?
以下是阿里巴巴集团智能计算研究院发布的Animate Anyone开源项目的Demo


案例基本完全一样?但是腾讯比阿里的视频长度更长,人物的动作幅度更大。
这完全对标模仿?刚开始看到时,我还感叹不愧是大厂竞争,直接贴脸开大,在你的基础上超越你?
但其实腾讯的MusePose项目除了修复了几个重要的错误之外,重点是在Moore-AnimateAnyone(阿里开源项目)的代码基础上做了一些改进。另外,腾讯在报告里也大大方方的致谢了阿里的开源项目以及其他的开源组件。

AI大模型的开源闭源,只不过是大厂之间相爱相杀罢了。但是我还是非常支持像腾讯和阿里这样的良性竞争多来点,咱们国内AI的发展必然未来可期!
当然MusePose当前版本也存在一些局限性,比如:难以保持细节一致性,原始角色的一些细节没有得到很好的保留(例如面部区域和复杂的服装);在复杂背景会出现噪声和闪烁。
期待下一个接力开源的大厂……
文章来源于“硅星GenAI”,作者“丸丸柚贝”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则