- 行业先锋
- 文章详情

刚刚,智谱AI开放日上,新一代MaaS平台2.0正式发布。
这次,GLM技术团队带来的是从模型,到成本、企业定制模型,以及业务场景的全面升级。
令人惊喜的是,第四代GLM系列开源模型GLM-4 9B,官宣开源免费用,还具备了多模态能力。同时,新发布的GLM-4-AIR性能媲美此前的最大基座模型,且价格降至1元/M token。
在5月这波价格战之后,国内主流大模型API调用已经直降超90%。
需要明白的是,即便token价格无限逼近零,企业需要搞清楚如何用才能发挥巨大业务价值。
否则,再便宜也是无用功。
这次的发布,直接将智谱AI带入了商业化的最后一站。新一代MaaS平台出场,便是一个很好的起点。
大模型2024:既要落地,又要开源
如果说2023年是世界发现生成式AI的一年,那么,2024年才是企业真正使用GenAI,并从中获得商业价值的一年。
麦肯锡最新的全球调查报告称,65%的受访者表示企业会经常使用生成式AI。
而这个数字,比十个月前的调查(33%),几乎翻了一番。

对于企业来说,从选用模型,到以低成本微调部署模型,并拥有灵活可用的全栈工具链,是让GenAI走向落地必不可少的过程。
那些无法「造血」没有自研模型的公司,就需要通过API、MaaS等平台,以便让LLM融入工作流。
比如,法律AI初创公司Harvey,通过OpenAI API,为律师们微调定制了一个「案例法模型」。
而且,经过测试,相较于GPT-4,有97%的律师更喜欢使用Harvey的模型。
而另一个典型的案例是,开源社区借助Llama 3之力,已经大大加速GenAI在医疗领域的应用。
在英伟达NIM推理微服务平台支持下,医疗开发者利用Llama 3已经开发出各种聊天助手、健康APP等。

反观国内,LLM落地究竟有多火,就从卷疯的token价格战,可一瞥而知。
API价格,已经卷疯
而在国产大模型的战场上,价格战也在最近卷出新高。
- 智谱AI开放平台的新用户,登录就送的500万token直接涨到2500万token
- GLM-3-Turbo每千token从0.005元直降到0.001元
- GLM-3 Turbo批处理API的价格也直接砍半,每千token砍到0.0005元

随后,火山引擎祭出更劲爆价格——豆包的企业定价直接击穿地心,千token低至0.0008元,比整个行业都便宜了99.3%。
智谱AI表示,基于技术突破、效率提升和成本控制三个因素综合的结果。通过大模型价格调整,更好满足开发者、客户需求。
当然,价格战仅是智谱AI贯彻MaaS战略中的一个「支点」。
大厂MaaS,如火如荼
大模型沸腾的热度,也让国内厂商的MaaS发展如火如荼。
所谓MaaS,即用户可以直接使用不同参数、不同规格的细分模型,来应对千变万化的应用场景。
商业链路打通后,蜂拥而至的开发者,就会让应用商店持续繁荣,形成「马太效应」。
今天的OpenDay上,智谱AI宣布MaaS平台不仅已经拥有了30万注册用户,而且模型的日均调用量也超过了400亿token。
在下面这条曲线中可以看出,在过去6个月中,智谱每日API的消耗量,增长了50倍以上。这正说明:已经有越来越多的企业,已经真正把模型用到了日常工作中。
GLM-4的API调用量则,则达到了90倍的增长。这也正说明,企业已经开始利用模型能力进入深水区,解决一些真正复杂的问题。

而今年,大家开始对于大模型有了一些新的期待——除了更强大、更快的模型,用户也开始对成本变得敏感。
模型升级:0.1元写2本《红楼梦》
如今,平台上已经全线接入新模型,由ChatGLM3-6B升级为GLM-4-9B,堪称“最能打的小模型”,已经全面超过了 Llama3-8B-Instruct。

在开放平台上,它变成GLM-4 Flash版本,价格相对于GLM-3-Turbo再次降价10倍,仅仅0.1元,就可以拥有一百万tokens,足够写两本四大名著了!

如果小模型不能满足需求,新推出的GLM-4-Air性能更加强大。它的性能跟和此前的GLM-4-0116相仿,但价格仅为前者的百分之一!一百万tokens,仅需一元。
而许多企业应用到深水区时,对速度也有极高的要求,在此基础之上,智谱加入了极速版。
效果不变,但推理速度直升162%。71 token每秒,相当于每秒可以直出100多个汉字!

并且,GLM-4-0116也同时升级了。
就在今天,智谱推出了GLM-4-0520,它的综合能力,已经提升了11.9%。
真正做过模型的应用的人,都明白这意味着什么:虽然在数字上看来只是一点点的提升,但这已经进一步提升了模型的天花板,极大扩展应用的范围,降低应用的成本。

如今,智谱AI已经拥有全模型矩阵。
无论是GLM-4V,还是CogView-3,降价都达到了50%-60%——一张图只需一毛钱。

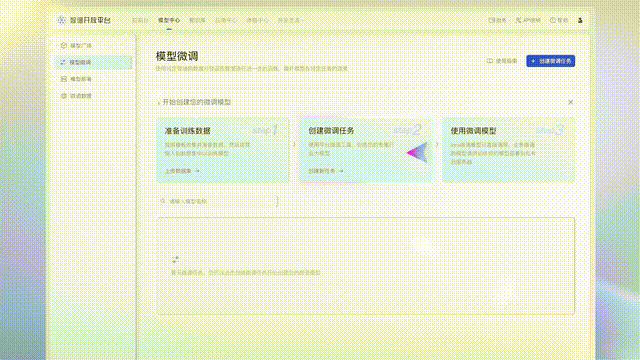
开放平台升级:3步训出一个私有模型
每个企业都希望构建自己的私有模型。虽然开源生态让模型训练门槛大幅降低,但对于绝大多数企业,这个过程依然太复杂。

为此,智谱AI也全面升级了自己的平台,仅仅三步——准备数据、创建微调任务、部署模型,就能让企业训出一个私有模型了!
这个过程中,不需要任何代码功底。而且,GLM-4全系列模型都支持这样的微调。

针对企业,智谱AI提供了两种模式:LoRA微调和全参微调。
LoRA微调,可以说是性价比之王,用更低的成本达到较好的结果。
全参微调,相当于是探索模型微调的极限。

可以看到,训练成本可以降低到87%。在LoRA微调上,GLM-4每千token只需要四毛钱,GLM-4-Air则只需要三分钱。
比起训练千亿模型动辄需要的多台A100、A800,显然门槛已经大幅降低。
而即使是全参微调的情况下,GLM-4每千token也只需要六毛钱,GLM-4-Air则只需要五分钱。
下面这个例子,是一个发生在客户身上的真实实验。
客户需要模型能够提供某领域专业化的咨询服务,于是,智谱AI尝试为客户做了微调。
他们选择了6000条语料,折合下来是一千万token。
训练后,模型的可用性从60%,直接上升到了89%!

这不是一个简单的提升,而是一个本质性的飞跃,让模型从不可用,变成了完全可用,进一步探索了模型使用的边界。
所以,这次微调的成本是多少?
答案令人惊诧——如果使用LoRA的话,成本仅为300元!即使选择全参,也只需要500元。

这个具体的demo,可以让我们深刻地体会到,如今训练出一个私有模型是多么容易。
另外,在AllTools的API平台上,智能体的能力能让大模型从解决一个单一任务,变成处理一个复杂任务。
在企业端,这样让使用模型的能力大幅度放开。
从此,每一家企业都能制作自己的智能体,以及智能体平台。
它可以让模型更好拆解任务,更好调用上下文function call的能力,还为企业提供了常用的一些智能体插件。
包括代码解释器、知识库检索增强、函数调用能力等等。

开放平台地址:bigmodel.cn
国内开源,影响世界
另一边,国内模型开源掀起的风浪,已然波及到全世界。
而坚持开源,是智谱AI一直以来的传统。
他们不仅是国产LLM的领头羊,也是大模型学术生态、开源生态中,不可忽视,首屈一指的中国力量。
目前为止,智谱AI已经有三代模型全部开源。
6B系列开源模型,在Github上已累计获得超过6万star,相当于Llama系列模型的star总数,超过了Grok和其他所有模型;在Hugging Face上吸引了超过1300万次下载,四周Hugging Face趋势榜第一。
GPT-4发布的同一天,团队首次开源了ChatGLM-6B模型,随后6月开源了二代6B模型,并首次引入GQA、FlashAttention技术,将模型上下文扩充到32K,并加速了生成速度。
紧接着10月,三代6B模型开源,支持128K上下文。

GLM-4 9B系列,免费开源
今天,智谱带来了第四代开源模型最新成果——GLM-4-9B。
显然,这次开源模型最大的变化是,参数规模从6B升级到了9B,并首次拥有了多模态能力。
而且,基于强大基座模型,GLM-4-9B不仅拥有更强的基础能力,更长的上下文,更精准的函数调用和All Tools能力。

比起上一代ChatGLM3-6B,在5倍的计算量下,GLM-4 9B的性能从61.4提升到了72.4,中英文综合能力提升40%。
另外,在与训练量更多的Llama-3-8B-Instruct较量中,GLM-4-9B毫不逊色。
具体来说,英文方面,第四代模型小幅领先,而在中文学科方面实现了50%的提升。

1M上下文,一次读完2本《红楼梦》
除此以外,GLM-4-9B的上下文从128K扩展到了1M,可同时处理200万字的输入。
这相当于,能够一次读完2本《红楼梦》,又或是125篇论文。
在长度为128K的LongBench-Chat上,GLM-4-9B-Chat模型相比上一代提升了20%。同时,在长度为1M的大海捞针测试中,GLM-4-9B-Chat-1M获得了「全绿」的成绩。


演示中,在1M版本模型中,输入《三体》的三本全集,共90万字的内容。
然后,给模型prompt「请仔细阅读上面的三部小说,如果让你给这个小说写第四部,你会怎么写,请给出大纲」。
模型给出了比较合理的续写规划。

另外,GLM-4-9B函数调用能力,比上一代大幅提升40%。
在UC伯克利函数调用Leaderboard上,9B模型函数调用能力,即可媲美GPT-4-Turbo。

智谱AI在开源仓库中,还提供了一个完整的All Tools Demo,开发者可以在本地拥有一个轻量级的清言平替。

比如,先用网页搜索「马拉松的世界纪录」,然后用代码解释器去计算「跑步平均速度」。


计算平均速度
All Tools还有非常多的组合,开发者可以自行去探索。
多模态比肩GPT-4V
除了文本模型,这次一并开源了多模态模型GLM-4V-9B。
最新模型采用了与CogVLM2相似的架构设计,能够处理高达1120 x 1120分辨率的输入,并通过降采样技术有效减少了token的开销。
与CogVLM的不同之处在于,GLM-4V-9B并没有通过引入额外的视觉专家来增加参数量,而是采用了直接混合文本和图片数据的方式进行训练。
这种训练方法使得GLM-4V-9B模型能够同时具备强大的文本和视觉处理能力,实现了真正的多模态学习。

它能够以13B总参数激活量,超越了一众多模态模型,甚至比肩GPT-4V。

不如看看,GLM-4V-9B在实际任务中的表现。
比如,让模型去识别T恤上的公式印花——麦克斯韦方程式。
你甚至,还可以追问关于方程组的细节,模型可以凭借自己的文本能力完成回答。
这从另一方面印证了,并没有因为引入多模态能力,而丧失模型原本的文本能力。

在下面这个例子中,是截取清华大学网络学堂的一个网页截图,并要求模型翻译成HTML代码。
GLM-4V-9B就可以识别出其中元素,并翻译成相应的代码。

整体来说,GLM-4-9B模型共有9.4B参数,是在10T的高质量多语言数据上,完成了预训练,几乎利用了所有网页数据。
其数据量是ChatGLM3-6B模型的3倍还要多。
与此同时,智谱AI采用了FP8精度进行高效的预训练并成功收敛,比起上一代模型,训练效率提升3.5倍。
由此,智谱AI将参数规模从6B扩展至9B,并将预训练计算量增加了5倍。
基于文本基座,打造的多模态模型GLM-4V-9B,完全融合了文本和视觉模型,并与GPT-4V不相上下。

成立于2019年,智谱AI用了4年的时间从一家明星创业公司,跻身为国内头部AI独角兽。
一直以来,外界对智谱的印象是,清华系国家队,全面对标OpenAI技术领先,to B气质强烈。
智谱不仅在大模型的能力上向OpenAI看齐,而且在投资领域布局上也不遑多让,深受资本青睐。

过去一年中,他们完成了3次基座大模型升级迭代,这次OpenDay 核心展示了面向AGI愿景的完整产品矩阵,透传出未来商业化的模式。
智谱AI正把MaaS商业模式提升到新的境界。MaaS平台2.0的诞生,将会进一步扩大智谱生态朋友圈。
文章来源于“新智元”,作者“新智元”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则