- 行业先锋
- 文章详情

5月14日凌晨,OpenAI终于发布了Sam Altman提前造势的“Magic(魔法)”,主要包括三个重点发布,ChatGPT新UI、桌面版GPT、以及最重要的,新的多模态模型GPT-4o。
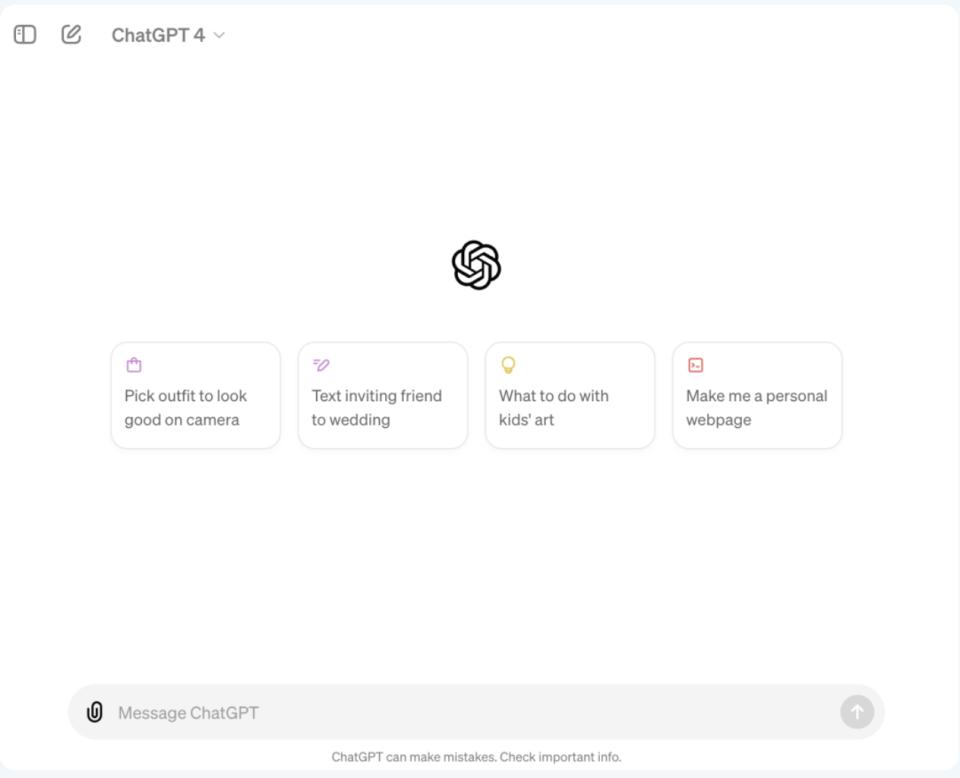
当模型变得越来越复杂,新的ChatGPT用户界面变得更加简洁,交互体验实际上变得更加自然和简单。
ChatGPT新UI
桌面版GPT实时在线,能随时帮你解决写代码、读图表等任务,且从演示视频看上去,桌面版GPT可以直接通过视觉等方式“读懂”你的任务,这大大提高了端侧任务处理的想象力。
最重磅的是新的模型GPT-4o。根据OpenAI的官网解释,”o”代表“全知”,是朝着更自然的人类与计算机交互迈出的一步。
总结下来,新模型GPT-4o有三大“魔法”:
①多模态:接受文本、音频、图像作为组合输入,并生成任何文本、音频和图像的组合输出。同时,在多模态理解能力中,最让人感到惊奇的是,它能够识别人类的感情,并根据感情做出“有感情的反应”。
②几乎无延迟:它对音频输入的响应时间最短为232毫秒,平均为320毫秒,这与人类在对话中的响应时间相似。
③可在电脑桌面运行,随时拥有一个AI队友,能随时帮你处理写代码、看图表等任务。
看完这三大特点,真的是直接感叹:“贾维斯”上线!“HER”闯进生活。从今天起,OpenAI给了你一个没延迟,有感情,可以随时看着你,无处不在的AI助理。还免费。本文的后半部分,将详细介绍GPT-4o解锁的新能力。
01 概览:GPT-4o是一个端到端的新模型
GPT-4o在英文文本和代码上与GPT-4 Turbo的性能相匹配,在非英文文本上有了显著提升,同时在API上速度更快,成本降低了50%。与现有模型相比,GPT-4o在视觉和音频理解方面尤其更好。
根据OpenAI发布在官网的最新博客文章显示,在GPT-4o之前,我们使用语音模式与ChatGPT对话,平均延迟为2.8秒(GPT-3.5)和5.4秒(GPT-4)。为了实现这一点,语音模式是由三个独立的模型组成的流水线:一个简单的模型将音频转录为文本,GPT-3.5或GPT-4接收文本并输出文本,第三个简单的模型将该文本再转换回音频。这个过程意味着主要的智能来源,GPT-4,丢失了很多信息,它不能直接观察语调、多个说话者或背景噪音,也不能输出笑声、歌唱或表达情感。
GPT-4o,是单独训练的新模型,可以端到端地处理文本、视觉和音频,这意味着所有输入和输出都由同一个神经网络处理。
GPT-4o并不是第一个端到端多模态模型。早在去年十二月,谷歌就已经发布了他们的Gemini模型。后续业界也一直判断OpenAI也会遵从大一统模型的模式,最终开发出端到端的多模态模式。
四个月过去了,OpenAI的大一统模型总算闪亮登场。还比谷歌的多了语音这一模态。
更重要的是,虽然大一统模型是谷歌先发,但OpenAI今天展示了一个更“真”的多模态模型到底应该达到什么水平。
02 新产品能力——魔法背后的魔法
魔法的基础:一体化多模态的多模态模型。传统文本、代码等推理能力没有质的提升,但音频视觉等能力达到新标准。
作为一个一体化的多模态模型,GPT-4o在传统基准测试中,文本推理和编程能力上达到GPT-4 Turbo水平,而在多语言、语音识别、语音翻译、视觉理解等方面创下新纪录。多模态能力的平均分高,是这个模型“魔法”能力的基础。

文本推理能力提高有限

与Whisper-v3相比,GPT-4o在多种语言的识别表现优异,尤其是小语种语言

GPT-4o在音频翻译表现上达到新的高水准

在多项基准测试上,分数都有提高,在视觉理解的测试上,GPT-4o达到新的高水准
易用性的魔法:OpenAI教苹果、谷歌做语音助手
虽然在能力上,大一统的多模态模型和Gemini一样并没带来想象中的性能巨幅提升。但OpenAI明显比谷歌多走了一步:用一个统合的助手在所有场景下应用所有这些多模态。
就从这次演示来看,这一交互层面的升级才证明了多模态确实是AI的Game Changer。
更强的是手机版的GPT-4o可以通过语音能力理解你的话语,状态(累不累,喘气粗不粗)。
还能通过视觉识别你所处的环境和你正在做的事情,并对它作出反应。帮你解数学题,没问题,解完还能陪你聊聊人生。
这就是OpenAI想做到的全知:一个陌生人看到你时所能感受到的几乎一切,它全部能接收到。因此它也有了真正能和你做与你私人相关的,符合场景的操作。
很多人会觉得这都是旧有的功能,因为不论是Gemini还是过去的GPT-4V,我们都可以截图给他们看当下的环境,他们也能识别照片中的信息并给你回应。语音,过去也有基于Whisper的识别系统,足以让上个版本的GPT4能回应你。
但这次GPT-4o带来的是对易用性体验的颠覆。
它能对实时环境产生理解,随时对已经变化的环境做反应,甚至还能借助记忆能力联系起这些变化。这比起过去不停截图给一个软件才能顺利对话的交互模式易用太多了。
除此之外,在演示中让人印象最深刻的是GPT-4o的快如闪电。与前代动辄2.6秒的反应速度相比,GPT-4o能毫无延迟的反馈对话。反应速度对用户体验的影响之大,想必产品经理们都熟记在心。
这就是得益于GPT-4o为多模态统一编码,并且是目前最真·多模态。因此我们不再需要语音转文本-问答-文本转语音(语音~文本-问答-文本~语音)这个传统的流程管线了。在GPT-4o中,可以直接做到语音-问答-语音,一步到位,大大缩短了反应时间。

Jim Fan演示的过去的三步走模式
同时,易用性还意味着更符合人类交互的习惯:GPT-4o在对话时可以随时被打断,且能接续的语音对话模式。


Jim Fan的赛前预测,满分
以上这三种能力的组合,让这个产品真正达到了用户用起来不觉得麻烦的水平。从今天起,AI终于成为了一个真正的常用陪伴型助手,而非只是我们需要求助时不情不愿调用的效率工具了。
这也许才是AI时代语音助手应该有的样子:随时可得,易用自然,功能强大。
正如美国知名技术布道者在会后第一时间提出的看法一样。

所以,Siri,谷歌语音助手,你们准备好了吗?
而Rabbit R1,AI Pin们,你们独特的价值还能存续吗?
除了语音助手本身,OpenAI 还通过新的GPT桌面版本展示了一下GPT-4o在桌面系统内能带来的改变。教了微软怎么叫真正的Copilot。
GPT-4o可以利用视觉能力识别出屏幕中你在写的代码,看的PDF,并给出总结或者提示。这比起GPT-4V的截图,上传文件也更易用自然;更比打开微软Copilot,用键盘在侧边栏提问交互易用自然太多。
沉浸性的魔法——有情感的机器
自然易用只是GPT-4o的基础操作,OpenAI真正让人感到深不可测技术力的其实是它让模型变得有“人味”了。
先看看这段对话,GPT-4o的回应简直自然的像是你的好闺蜜,情绪饱满到几乎与真人毫无差别:她会惊讶,会笑,会随着你的情绪激动起来,语气中充满了细节。这和过往虽然也能模仿人类语调,但总归是缺了点真人情绪反馈的GPT4相比,太像人了。
尤其是这些情绪变化都非常贴合上下文和对话的场景,就好像她知道什么时候该表现出什么情绪一样。
另一个例子也可以证明它是真的懂“情绪”是什么。在Demo过程中,当测试者要求它用“最戏剧性”的方式去讲故事的时候,她表现的和一个话剧演员几乎没什么差别了。这需要她懂得“戏剧性”这一在很大程度上形容情绪强度的词汇是什么意思。
除了自身会表达情绪,GPT-4o还有个“情绪探查器”,能够读懂你的情感。结合之前的演示,它也能从你的语气中理解你的状态。
这些性能不由让人想起在3月27日,Hume AI刚刚的发布第一个能识别人类感情的AI——Evi,它能通过人类的声音语调判断出63种情感的综合。这在当时引发了业界的相当震动。
但它能做到的仅仅是识别感情,而非能够应对人类的感情来生成富有感情的语句。

但现在GPT-4o似乎做到了这个堪称魔法的能力。
这意味着更加可信的对话对象,一个你会不光从能力角度上觉得它有智力,而是从交流感受上觉得它像人的AI诞生了。这将意味着前所未有的交互性沉浸感。
正如Sam Altamn所说,正是在这个背景下,属于每个人的云端情人HER到来了。
可惜的是,OpenAI的技术文档对此只字未提。我们也无法对它进行更深入的解读了。一个可能的猜测是,这是OpenAI在训练端到端语音模型中自发涌现出的一种新的模型能力。
可以想见的是,在GPT-4o的魔法影响下,AI交友、AI心理咨询师等等所有需要强情绪交互的赛道都会很快就变成一片蓝海。
魔法之旅刚刚开始,真·多模态的能力也许远不止于此
情感识别和适配,也许是GPT-4o作为统一多模态模型所涌现出来的一种非常强大的能力。但它潜在的可能性并不止于。如Greg Brockman在推特上的发声,GPT-4o通过音频、文本、图像输出的任意组合,可以无限解锁新的功能。而OpneAI对这些新涌现也不过只是瞥见了一小部分。

这一小部分也已经非常惊人了。除了在直播中重点强调的功能,在OpenAI的技术文档中,我们看到在GPT4-o的能力列表中,还包含3D能力、图像诗能力、转换卡通照片等能力。

图注:OpenAI官方Blog中的能力探索列表
比如:生成3D模型的魔法

像波德莱尔那帮现代主义诗人一样,用诗歌或logo填满规定的形象。

潜在的粘土人能力,只不过OpenAI选的是把现实头像转换卡通图像

这一切都说明, GPT-4o给我们可能带来的惊喜可能还远不止如此。
03 其它值得注意的小细节
1、GPT-4o采用全新的tokenizer,大幅提高了对各种语言的编码效率,比如古吉拉特语的token数减少了4.4倍,这其中包括20种语言,如英语、法语、德语、葡萄牙语、西班牙语等,其中也包括中文。
2、 模型安全性和局限性
根据OpenAI的安全评估,GPT-4o在网络安全等风险维度上都控制在中等水平以下。但其语音模态带来一些新的安全挑战,需要持续迭代改进。目前向公众开放的是文本和图像输入,以及文本输出。语音输出将限定为预设的声音,这意味着,语音的克隆还是会有某些限制,OpenAI未来将分享更多细节。
3、Sam Altman上线”承认“,GPT-4o就是前两天放出来的I’m a good gpt2 chatbot

04 免费,降价,OpenAI想尽办法让你在几周后就用上它
不是期货,马上就能用。GPT-4o的文本和图像能力今天开始在ChatGPT中推出。在免费版中提供GPT-4o,并为Plus用户提供高达5倍的消息限制。在未来几周内,将在ChatGPT Plus中推出带有GPT-4o的语音模式新版本。
开发者现在也可以通过API以文本和视觉模型的形式访问GPT-4o。与GPT-4 Turbo相比,GPT-4o的速度提高了2倍,价格降低了一半,速率限制提高了5倍。OpenAI计划在未来几周内向API中的一小部分信任合作伙伴推出对GPT-4o的新音频和视频能力的支持。
与GPT4-turbo对比:
GPT-4o
输入:$5.00 / 1M tokens
输出:$15.00 / 1M tokens
GPT4-turbo:
输入:$10.00 / 1M tokens
输出:$30.00 / 1M tokens
本文来自微信公众号“腾讯科技”(ID:qqtech),作者:郭晓静、郝博阳

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则