- 行业先锋
- 文章详情

时隔七十多天,面壁在发布了MiniCPM-2B后又带来四个特性鲜明的模型,同时它还官宣了数亿元的新融资。
此次融资由春华创投、华为哈勃领投,北京市人工智能产业投资基金等跟投,知乎作为战略股东持续跟投支持。这是其成立后最大的一笔融资。这家常被拿来对标Mistral的公司,并不满足于只做一个“中国Mistral”,弹药充足后,它要把“打精锐”这件事进行到底了。
1
小而强,小而全:小钢炮四连发
今年二月初,面壁智能发布了2B参数的开源端侧模型MiniCPM-2B,并称之为“小钢炮”,在更小参数的基础上实现了Mistral-7B、Llama2-13B的性能。自发布以来,MiniCPM-2B多次登顶 GitHub Trending,还收获了HuggingFace联合创始人Thomas Wolf的称赞。
时隔七十多天,面壁智能一次性发布了四个模型,我们来看看它们的表现。
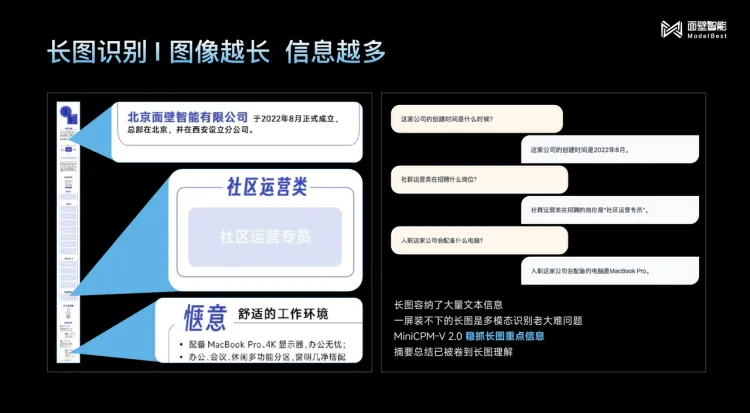
多模态模型 MiniCPM-V 2.0
MiniCPM-V 2.0是可部署在手机端的多模态大模型,规模只有2.8B左右,但在主流的评测中取得了很好的分数。OpenCompass榜单,综合11个主流评测基准,通用能力超过Qwen-VL-Chat-10B、CogVLM-Chat-17B、Yi-LV-34B。
面壁智能特别强调了MiniCPM-V 2.0的幻觉概率很低,与持平GPT-4V,在评估大模型幻觉的Object HalBench榜单上,MiniCPM-V 2.0是14.5%,GPT-4V是13.6%。
MiniCPM-V2.0在OCR能力方面,场景图片文字识别榜单TextVQA超越了全系13B量级模型,比肩Gemini Pro。MiniCPM-V2.0 还加强了对于长图的识别和理解,以及对各种尺寸图片的兼容进行了优化,支持从448×448像素,到180万像素的高清大图,也支持1:9的极限宽高比。

长文本模型MiniCPM-2B-128K
长文本已然成为大模型的一种“标配”,而MiniCPM-2B-128K用2B的规模实现了128K长文本能力,在InfiniteBench榜单的平均成绩超过Yarn-Mistral-7B-128K、Yi-6B-200K、ChatGLM3-6B-128K、LWM-Text-128K,在7B以下的模型中做到了最好的表现。
“长文本这件事情才刚刚开始,虽然是2B的模型,还是需要非常大的内存才能让模型跑起来,下一步会进一步做更加极致的技术探索,让长文本模型在端侧跑起来。”

MOE版本 MiniCPM-MoE-8x2B MoE
MiniCPM-MoE-8x2B MoE,引入了MoE架构,性能增强,能让模型在原有基础上平均水平有4.5%的提高。相比完全从头开始训练,节省训练成本。通过MOE的方式,平均激活参数只有4B,但是比LiaMA2-34B、Gemma-7B等模型效果都要好,推理成本仅为Gemma-7B的69.7%。
“更Mini”的MiniCPM-1.2B
MiniCPM-1.2B参数减少了一半,而能够保持仍保持上一代2.4B模型87%的综合性能,这其中涉及许多优化,例如把词表中不高频的词替换。在多个榜单测试中,MiniCPM-1.2B综合性能超过Qwen1.8B、llama2-7B,甚至超过llama2-13B。

通过让1.2B的模型效果超过了1.8B的模型,实现了手机端 25tokens/s。随着模型的变小,成本、和内存占用也随之降低,相比于MiniCPM-2.4B,MiniCPM-1.2B内存减少51.9%,成本下降60%。
“模型小了,使用场景大了”。MiniCPM-1.2B除了能够支持配置更低的手机,在诸如情感陪护、实时翻译等应用场景都有着广泛的应用。“他们对于更小更强的模型都是非常期待的”。
1
不止于“中国版Mistral”
面壁智能CEO李大海将此次发布的系列模型总结为“小而强,小而全”,并再次强调了面壁智能的底层逻辑:一家追求高效大模型的公司。这很容易让人联想到同样是追求高效,同样做小参数高性能模型,同样受到开源社区追捧的“欧洲Open AI”Mistral。
不过面壁智能显然不想只是做第二家Mistral,这家聚集了中国最早一批研究大模型的技术人员的公司有着自己鲜明的技术判断和产品路线。
面壁智能高效训练的方法论体现在模型训练实验科学化的思路上,在基础设施上,面壁智能很早就自研了BMTrAIn等框架来支撑大模型的训练,从而降低训练成本。
在算法层面上,面壁智能通过进行大量的“沙盒实验”,对模型批次大小、超参数配置等最优训练配置进行了探索,从理论上寻找最优解,用更小的成本和代价去搞清楚规律。比如在较小参数的模型上做大量沙盒实验,通过科学化实验化的“炼丹”,用小模型预估更大规模参数模型的性能、参数方案,最终实现以小博大。
“持续研究更好的ScalingLaw,用更大的模型压缩效果,用更少的数据训练出更好的模型、更小的模型。”
此外,在基础模型之外,面壁的另一个重点方向在AI Agent,这也与Mistral很不同。
面壁智能是最早进行Agent研究的团队之一,ChatDev是面壁智能联合OpenBMB 及清华大学NLP实验室开源的大模型+Agent项目,ChatDev就像是多个Agent协作运营的软件开发公司,用户指定需求后,不同角色的Agent进行交互式协同,产出包括源代码、环境依赖说明书、用户手册在内的完整软件。通过多智能体协作,可以在现有模型中产生更好的效果。这也就是吴恩达近期在红杉AI峰会上所说的GPT3.5 + Agentic Workflow >GPT4,实际上,吴恩达在演讲中直接使用了ChatDev作为案例。
Agent是面壁智能商业化的重要突破口,ChatDev也从论文研究、开源产品,开始走向了商业化,面壁智能推出了AI Agent的SaaS化产品ChatDev,尝试帮助软件开发者和创业者以更低成本和门槛完成软件开发工作。与此同时,面壁智能也在探索大模型+Agent在金融、教育、政务、智能终端等场景的商业应用落地。
OpenAI用大力出奇迹提供了一条通往AGI的路径,但抵达彼岸的方法并非只有一条。在疯狂烧钱拼算力的大模型行业,仅靠单一维度的提升会出现瓶颈,而且这种提升可能会受到边际效益递减的影响。面壁智能用实验科学的方式做基础模型研究,强调高效,某种程度上追求的是一种“性价比”。在相同资源的情况下,面壁可以利用“高效”的杠杆获得更高的收益。MiniCPM系列模型已经证明了在相同的资源内把模型做得更好是可行的,接下来可以期待面壁延续这个思路,拿出GPT-4级别的模型产品。
相较之下,Mistral虽然在推出了号称挑战GPT-4的大模型产品,但不仅在商业模式上越来越却像OpenAI,Mistral Large也不再开源,这让人开始质疑,拿了微软投资之后的Mistral,是否走上了OpenAI的老路,最终成为微软的又一个“附庸”。
如果说追求高效是面壁智能和Mistral相同之处,而对于Agent的研究投入和积累,又让面壁这家公司拥有了不同的商业化道路。从网站到App,我们见证了互联网原生应用主要载体的变迁,在AI时代,Agent具备了新的潜力,小钢炮们又成为挖掘这种潜力的最佳载体。
从对标Mistral 、再到超越Mistral,面壁智能或许选择了一条少有人走的路,但它已经有了足够的底气继续走下去。
本文来自微信公众号“硅星人pro”,作者 周一笑

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则