- 行业先锋
- 文章详情

不得不感叹,国外AI大模型的迭代速度,就像是坐火箭????。
9日至10日,大模型的世界可谓是热闹非凡,各路科技巨头争相发布新版本,那速度简直堪比咱们刷朋友圈的速度,一刻不停歇。
首先,OpenAI把GPT-4的消息限制给取消了,你以为这样就够了吗?错!他们还发布了视觉版的GPT-4 Turbo,不仅能读图,还能理解长长的上下文。然后,谷歌不甘落后,更新了Gemini模型,让它不仅能理解音频,还能处理无数文件。这速度,这功能,让人眼花缭乱。
科技巨头们也加入了这场战局,苹果发布了Ferret-UI,专攻UI界面的理解,开源巨头Mistral也发布超大杯,天下苦OpenAI 闭源久矣的局面或要结束。
我们不禁疑惑,这是要干嘛? 是要组团飞向下一科学纬度吗?
谷歌更新Gemini模型,识别出谁在讲话
一直憋着大招的谷歌,总想悄悄战胜OpenAI。
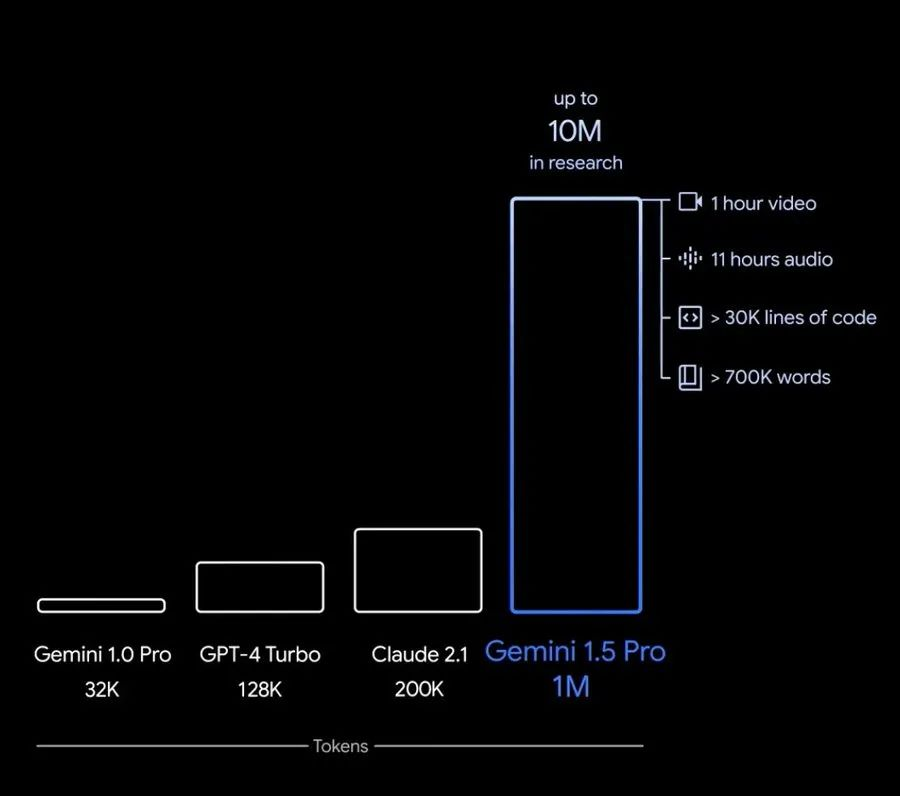
这不,Gemini模型又进行了一波大更新。最新版本Gemini 1.5 Pro 它可以处理多达 100 万个ToKen,相当于超过700,000字 、超过 30,000 行代码 、11小时的音频 、 1小时视频。
现在Gemini不仅能听懂音频,理解多达9.5小时的音频内容,还能察觉到你的情感,甚至可以听到背景音,简直是AI界的心理咨询师。
而且,它还能处理无限量的文件,这存储能力,比我云盘里的照片还多。
Gemini在功能调用和系统指令上也做了不少改进,可以选择模式来限制输出,提高可靠性。最重要的是,它推出了JSON模式,可以从文本或图像中提取结构化数据。这是不是意味着,以后想要从网上找数据,直接扔给Gemini就行啦?
有网友真做了这个试验,将一个NBA视频扔给了Gemini。

它在“看到”了这个 11 分钟的 Youtube 视频(~175kTokens),其中包含体育界最具标志性的时刻,并且能够完美地列出所有 18 个时刻。

OpenAI 正式发布GPT-4 Turbo,带上读图能力
说起来,OpenAI这家公司还真是会捉弄人,每次看到谷歌大模型更新后,都会隔2小时发布最新的ChatGPT版本。
此前,OpenAI 先是给GPT-4设了个每3小时40条消息的限制,让不少用户在尝试了10到17条消息后,就被无情地告知:您已达到上限。但突然有一天,他们就像变魔术一样,把这个限制给取消了!取消了!
这下好了,不限量了,想问啥就问啥,GPT-4突然变得像是知无不言的智者。但这还不算完,OpenAI正式发布GPT-4 Turbo后(此前是预览版本),不仅能处理128k的上下文,还自带了读图能力。
要说这个GPT-4 Turbo,那可真是个大块头,能力升级得跟超级英雄似的。它的基础能力得到了极大的提升,官方说法是“Majorly improved”,听起来像是吃了大力丸一样。这个版本不仅能够理解更长的文本,还能直接解读图片,省去了之前还要用4v接口的麻烦。
这货的训练数据截止到2023年12月,可以说是相当的新鲜。而且,它还增加了一个重量级的功能——128k上下文的理解能力。这是什么概念?也就是说,你给它的信息越多,它理解得越透彻,反应越迅速,简直就是AI界的“记忆大师”。
不过,新的 GPT-4 Turbo 模型在 aider 的重构基准测试中得分仅为 33%,使其成为所有 GPT-4 Turbo 模型中最懒惰的程序员 这意味着,它比现有的 GPT-4 Turbo“预览”模型更容易出现“延迟编码”。

苹果首次入局大模型,另一开源巨头也更新了
科技巨头苹果也不甘落后,发布了Ferret-UI,这个MLLM专门为了理解移动UI屏幕而设计。
它不仅能够理解屏幕上的内容,还能识别和操作具体的UI元素。简单来说,未来可能通过Siri就能自动操作应用界面,这不就是懒人的福音嘛!

具体来看,在识别传统图像(例如 GPT-4V)的 MLLM 的情况下,它会识别应用程序中的元素,比如:
– 图标识别:识别屏幕上的图标 – 查找文本:识别界面中的文本 – 列出小部件:列出屏幕上可用的小部件 – 详细说明:描述您正在查看的屏幕 – 认知/交互对话:基于屏幕感知进行对话交互

苹果最近的论文也是关于苹果的界面、用户体验,大多数时候都是关于了解用户设备上的界面。得说苹果的多模态大模型,方向有点特殊,但好在自己下场了,感觉是想手机端用自己的大模型,识别用户和APP交互的意图,云端依靠其他家大模型的能力。
与此同时,Mixtrail 8x22B模型发布。这家此前被誉为欧洲仅次于GPT4的大模型企业,是国际上的开源三巨头之一。
这次发布的Mistral 8x22B 是去年开源的「mixtral-8x7b」的超级大杯版本,参数规模增长三倍不止 —— 由 8 个 220 亿参数规模 (8×22B) 的专家网络组成。
作为一款全新的 8x22B MoE 模型,上下文长度为 65k。
有推特网友评价,法国这家AI小小厂再一次吊打了中国大陆目前一切大模型产品。
吊没吊打暂且不提,我们每一个昏睡的夜晚,很多国际大模型企业都在疯狂更新,正如这位机器学习研究人员所言:
在过去的 24 小时内,我们得到了 Mixtral 8x22B、Unsloth 疯狂的性能升级、Google 的全新架构优于 Transformers (Griffin)、llama.cpp 的 Command R+ 支持,以及 Llama 3 的消息!
如果这不是一个革命的时代,那是什么?
咱们国内的大模型,现在也是风起云涌的状态。不过,跟国际上的巨头们一比,给人的惊喜度显然不够。当然,这并不是说我们做得不好,只是在AI这个战场上,每个人都在全力以赴,稍有松懈,就可能被对手超越。
本文来自微信公众号“AI鲸选社”(ID:aijingxuanshe),作者:到底哥

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则