- 行业先锋
- 文章详情

对代码大模型而言,比能做编程题更重要的,是看是能不能适用于企业级项目开发,是看在实际软件开发场景中用得顺不顺手、成本高不高、能否精准契合业务需求,后者才是开发者关心的硬实力。
当下,大语言模型集成至编程领域、完成代码生成与补全任务成为重要趋势。业界已经出现了一批引人瞩目的代码大模型,比如 OpenAI 的 CodeX、谷歌 DeepMind 的 AlphaCode、HuggingFace 的 StarCoder,帮助程序员更迅捷、更准确、更高质量地完成编码任务,大幅提升效率。
有这样一支研发团队,在 10 年前便开始了将深度学习用于软件开发的探索,并在代码理解和代码生成领域双双全球领先。他们就是来自北京大学软件工程研究所的 AIXcoder 团队(简称 aiXcoder 团队),此次为开发者带来了新的高效编码利器。
4 月 9 日,该团队开源了全自研 aiXcoder 7B 代码大模型,不仅在代码生成和补全任务中大幅领先同量级甚至超越 15B、34B 参数量级的代码大模型;还凭借其在个性化训练、私有化部署、定制化开发方面的独有优势,成为最适合企业应用、最能满足个性化开发需求的代码大模型。
aiXcoder 7B 的全部模型参数和推理代码均已开源,可以通过 GitHub、Hugging Face、Gitee 和 GitLink 等平台访问。
「耳听为虚眼见为实」,一切还是要用真实的测评数据和实际的任务效果说话。
越级体验
能其他代码大模型所不能
一个代码大模型究竟好不好用, 当然要在对程序员最有帮助、用的最多的代码生成与补全任务中来验证。
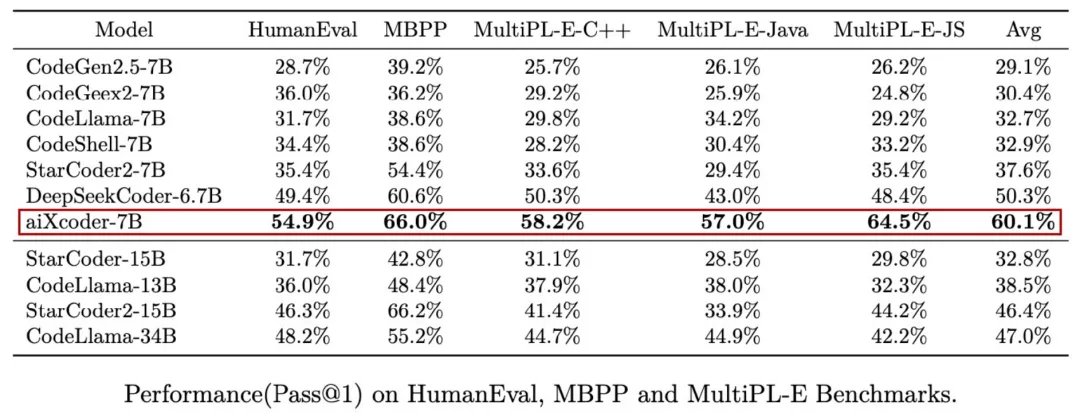
先看代码生成比较结果,在 OpenAI HumanEval(由 164 道 Python 编程问题组成)、谷歌 MBPP(由 974 个 Python 编程问题组成)和 HuggingFace MultiPL-E(包含了 18 种编程语言)等代码生成效果评估测试集上,aiXcoder 7B 版的准确率远超当前主流代码大模型,成为十亿乃至百亿级参数中最强。
除了在 HumanEval 这样偏向非真实开发场景的测试集上取得准确率新 SOTA,aiXcoder 7B 在代码补全等真实开发场景中的表现更是可圈可点,比如写好上文让代码大模型补下文或者跨文件引用已经定义好的方法、函数、类等。
同样用数据说话,在考虑上下文的单行补全测评集 SantaCoder 上,aiXcoder 7B Base 版在与 StarCoder 2、CodeLlama 7B/13B、DeepSeekCoder 7B 等主流同量级开源模型的较量中取得最佳效果,成为最适合实际编程场景的代码补全基础模型。具体如下表所示:

aiXcoder 7B Base 版的补全效果最好,不单单是准确率更高,还在实际运行中表现出了其他代码大模型没有或者逊于自己的能力。实现这些的背后是一系列针对代码特性的创新训练方法,正是它们使得 aiXcoder 7B Base 版脱颖而出。
首先,aiXcoder 7B Base 版在预训练时提供了 32k 的上下文长度,这在现有 7B 参数量级代码大模型中为最大,其他多为 16k。不仅如此,通过插值的方法可以直接在推理时将上下文长度扩展到 256k,并在理论上有能力扩展至更长。
在同量级模型中拥有最大预训练上下文长度,并可弹性扩展,成为提升 aiXcoder 7B Base 版代码补全效果的重要基础。
其次,aiXcoder 7B Base 版在代码补全过程中「知道」用户什么时候需要生成代码,并在代码内容已经完整不需要再生成时自动停止。这成为该模型比较独特的功能,其他很多代码大模型无法做到这一点。
aiXcoder 团队表示,该功能在技术上的实现离不开结构化 Span 技术。在模型训练中,通过结构化 Span 技术来构建训练数据和相关任务,让模型学习到用户应该在什么时候生成代码或者补全的内容在语法和语义结构上是否完整。
这也就意味着 aiXcoder 7B Base 版能自动「知道」自己推理到了什么位置,而其他模型想要终止的话,需要人为设定终止条件。自动推理则少了这种麻烦,有助于提升工作效率。
此外,在 aiXcoder 扩展基准测试集(aiXcoder Bench)上,aiXcoder 7B Base 版表现出了相较于其他代码大模型的又一大亮点,即倾向于使用较短代码来完成用户指定的任务。
详细结果如下表所示,在针对 Java、C++、JavaScript 和 Python 编程语言的代码补全测评时,aiXcoder 7B Base 不仅效果最好,四处红框圈出的生成答案长度明显短于其他竞品模型,并且非常接近甚至有时比标准答案(Ref)还要短。

aiXcoder 团队指出,这一后验发现仍离不开结构化 Span 技术。他们在整个训练过程中特别注重代码结构,而结构化 Span 按照代码结构对代码进行拆分,这更有益于体现代码的语义,最终促成了模型「短」答案的同时效果又占优。
除了在以上单文件上下文代码补全任务中的卓越表现,aiXcoder 7B Base 版在跨多文件补全场景中的表现同样更胜一筹,不仅针对多文件的编程效果提升最优,还在下表 CrossCodeEval 测评集上有了一个重要发现。
据 aiXcoder 团队介绍,该模型在只通过光标上文搜索到的结果作为 prompt(只看当前编写的上文),同时其他模型拿 GroundTruth(把包含答案的文件给到这些模型)搜索到的结果作为 prompt,在这种条件下,前者的效果依然要强于后者。
如何做到的呢?对于其他模型来说,即使有更多的上下文信息,它们也搞不清楚哪些是最核心、最关键的。而 aiXcoder 7B Base 版能从上下文档中拣出对当前编写代码最有效、最核心的上下文细节,所以才有好的效果。
这里感知到哪些信息最有效最为关键,通过对上下文进一步信息处理,结合文件相关内容的聚类、代码 Calling Graph 来构建多文件之间的相互注意力关系,进而获取到对当前补全或生成任务最关键的信息。

所有这些创新性训练方法很大程度上决定了 aiXcoder 7B Base 版能够在众多代码大模型的比拼中胜出。此外, 1.2T 的高质量训练数据同样功不可没,这一量级不仅在同类型模型中最大,还是独有 token 数据。
其中 600G 优先放入的高质量数据对模型效果起了重要作用,其他数据主要来自 GitHub,以及 Stack Overflow、Gitee 等,自然语言部分还包括了一部分 CSDN 数据,并且全部数据进行了过滤处理。
Talk is cheap, Show me the code
显然,aiXcoder 7B Base 版在测评数据上赢了其他代码大模型,但究竟能不能高效地帮助开发者完成编码任务?还是要看实战效果。
先看生成能力,对于前端开发,aiXcoder 7B Base 版可以通过注释快速地生成对应网页:

还可以处理高难度算法题,比如经典的分糖果问题,通过贪心的策略,以左右两次遍历的方式得到最少糖果数。

再来看 aiXcoder 7B Base 版更得心应手的代码补全场景,比如长上下文补全。这里用多个工具函数拼成 1500 多行的代码,要求模型在文件末端进行注释补全,模型识别到了文件顶部的相关函数,并成功地结合函数信息补全了相关方法:

还有以下跨文件补全任务,在树结构上应用动态规划来实现编辑距离搜索。模型补全的代码识别到了编辑距离的计算与另一个文件中滚动数组内部取最小值的计算之间的关系,并给出了正确的预测结果:

当然还可以智能化匹配输出长度。当用户调整自己的采纳内容时,模型能够根据当前的采纳情况自动调整补全长度:

一句话,有了 aiXcoder 7B Base 版代码大模型,无论是代码生成还是补全,程序员多了一个效率提升利器,节省时间,事半功倍。
拼效果,更拼应用
用核心竞争力成为企业首选
我们已经看到,aiXcoder 7B Base 版在代码补全这样的真实开发场景中充分展现了自身的硬实力。不过,对于企业客户来说,代码大模型只是效果好并不能完全打动他们。只有全方位满足自身需求,企业客户才会毫不犹豫地下手。
aiXcoder 7B Base 版正是奔着企业需要、解决他们的个性化需求来的。打造最适合企业应用的代码大模型,成为了 aiXcoder 7B Base 版的首要目标和有别于其他模型的又一核心优势。
当然,想要成为企业应用的最佳选择并不容易,必须围绕着企业业务场景、需求、所能承担的成本等实际情况做深文章。aiXcoder 模型不仅这样做了,而且做到了极致。
简而言之,为了实现企业级个性化的应用落地,aiXcoder 模型在私有化部署、个性化训练和定制化开发三个方面齐发力,打造出了相较于其他代码大模型的核心优势。
首先来看私有化部署。对于企业而言,代码大模型在本地服务器的私有化部署和运行,首要考虑的是自身算力是否可以支撑。在这点上,aiXcoder 模型对企业 GPU 资源要求少,应用成本投入低,让部署模型门槛大大降低。
此外,不同企业拥有的软硬件各异,既会有国产芯片,也会有国外如英伟达显卡。基于此,aiXcoder 模型进行针对性硬件适配以及进一步模型训练和推理优化,比如在信息处理层面采用高速缓存技术,充分满足多样化部署要求。
其次也是 aiXcoder 模型着重强调的个性化训练。我们知道,企业的实际情况不能一概而论,而 aiXcoder 模型做到了见招拆招,提供了「一揽子」的个性化模型训练解决方案。
一方面构建企业专属数据集和测评集,其中数据集构建基于企业代码特征和员工编码习惯,专门对代码及相关文档进行数据预处理;测评集构建则以真实开发场景为准绳,模拟并评估模型在实际应用中的预期效果。
另一方面,将企业代码这一内因与企业算力资源这一外因相结合,充分考虑到不同企业计算资源、代码量的多寡,为他们提供灵活的个性化训练及优化方案,最大化提升专属代码大模型的前期训练效果和后续应用效果。
第三是定制化开发。aiXcoder 模型瞄准不同行业和企业的实际情况,结合企业个性化需求来为他们提供灵活的定制化服务。凭借丰富和成熟的定制开发经验,让基于企业代码和计算资源打造的模型高度契合实际需求,让业务效率的提升看得见摸得着。目前,客户已经遍布银行、证券、保险、军工、运营商、能源、交通等多个行业。
可以看到,相较于其他代码大模型,aiXcoder 能同时为企业提供个性化训练的产品和服务,这在业内是唯一一个。
背后团队
十年深耕、厚积薄发
此次 aiXcoder 7B Base 版代码大模型展现出来的编码能力,让我们更加好奇模型背后的团队。
据了解,aiXcoder 团队从 2013 年开始了基于深度学习的代码分析研究,是全球最早将深度学习技术应用于代码生成与代码理解领域的团队。
十年来,团队在 NeurIPS、ACL、IJCAI、ICSE、FSE、ASE 等顶会上发表相关论文 100 余篇,多篇论文被国际学者认为是「首创成果」并被广泛引用,多次获 ACM 杰出论文奖。
2017 年,aiXcoder 有了雏形,并在 2018 年正式发布 aiXcoder 1.0,提供代码自动补全与搜索功能。

2021 年 4 月,团队推出完全自主知识产权的十亿级参数代码大模型 aiXcoder L 版,支持代码补全和自然语言推荐。这也是国内⾸个基于「⼤模型」的智能编程商⽤产品。
而后,团队持续攻坚,2022 年 6 月再次推出了国内首个支持方法级代码生成的模型 aiXcoder XL 版,同样具有完全自主知识产权。
2023 年 8 月,聚焦企业适配的 aiXcoder Europa 上线,可以根据企业的数据安全和算力要求,为他们提供私有化部署和个性化训练服务,有效降低代码大模型的应用门槛,提升开发效率。
到了此次,aiXcoder 团队开源 aiXcoder 7B Base 版,将已经住考验的全新代码大模型带给大家。一方面,该模型以 7B 参数规模在代码补全等真实开发场景中表现出的越级能力及其在企业适配方面的多项核心竞争力,有助于推动代码大模型行业的整体进步。另一方面,该模型将对更广泛的软件开发自动化产生深远的影响,在加速这一进程的同时为各行各业持续提升业务效率、变革生产方式保驾护航。
不仅如此,相较于同样具备代码能力的通用模型,aiXcoder 7B Base 版让我们看到了专用代码大模型更低训练和推理成本、企业部署成本以及在企业项目级代码上更好、更稳定效果的全方位优势。
目前,aiXcoder 已服务大量银行、证券、保险、军工、高科技、运营商、能源、交通等行业头部客户,深耕服务金融行业,其中与某行业知名券商的「代码大模型在证券行业的应用实践」项目荣获 2023AIIA 人工智能十大潜力应用案例、中国信通院 AI4SE 银弹优秀案例等殊荣。
同时,aiXcoder 也因其极具前瞻性的探索方向、踏踏实实的落地实践,不断受到资本市场的追捧,高瓴、清流、彬复等极具行业引领性的基金纷纷加注 aiXcoder 团队,使其得以迅速成长!
显然,在未来 AIGC 的这场较量中,aiXcoder 团队已经做好了准备。
aiXcoder 开源链接:
https://github.com/aixcoder-plugin/aiXcoder-7B
https://gitee.com/aixcoder-model/aixcoder-7b
https://www.gitlink.org.cn/aixcoder/aixcoder-7b-model
https://wisemodel.cn/codes/aiXcoder/aiXcoder-7b
文章来源公众号“机器之心”,作者“杜伟”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则