- 行业先锋
- 文章详情

“你能算出一个苹果有多少种子,但是永远不知道一颗种子能结多少苹果。” 科技也是一样。 很多时候,我们将科技看为一个结果,一个苹果,但其实科技是一颗种子,是一个开始。绿洲相信人工智能带来的社会变革,绿洲更加相信人工智能只是整个人类进入智能时代的其中一个截面,而具身智能正是另外一个截面。 正是这个相信,在过去两年市场冷清的时候,绿洲加速了具身智能领域的基础设施投资。所以今年开始,在人工智能全球专家对谈之外,我们期待和大家分享更多我们关于具身智能的理解和观察,期待大家多多交流,共同种出更多的苹果。
Part I
AI 跃迁,机器人进入新的发展代际
构建以第一人称视角,实现自主感知 – 规划决策 – 自主执行闭环、能在各种场景自适应的智能通用机器人,一直是机器人和 AI 领域的长期目标,而传统机器人系统往往难以实现以上功能。自 GPT-3 问世以来,AI 的蓬勃发展取得了令人瞩目的成绩,近年各类 LLMs&LVMs 大模型的问世,为机器人领域带来了新曙光:能理解、推理、并与物理世界产生交互的智能系统——具身智能理念应运而生。对于 AI 而言,具身智能是通用 AI 实现与物理世界交互的关键载体和入口;对于机器人领域,具身智能则将引领机器人进入通用化的新代际。
从过去看现在
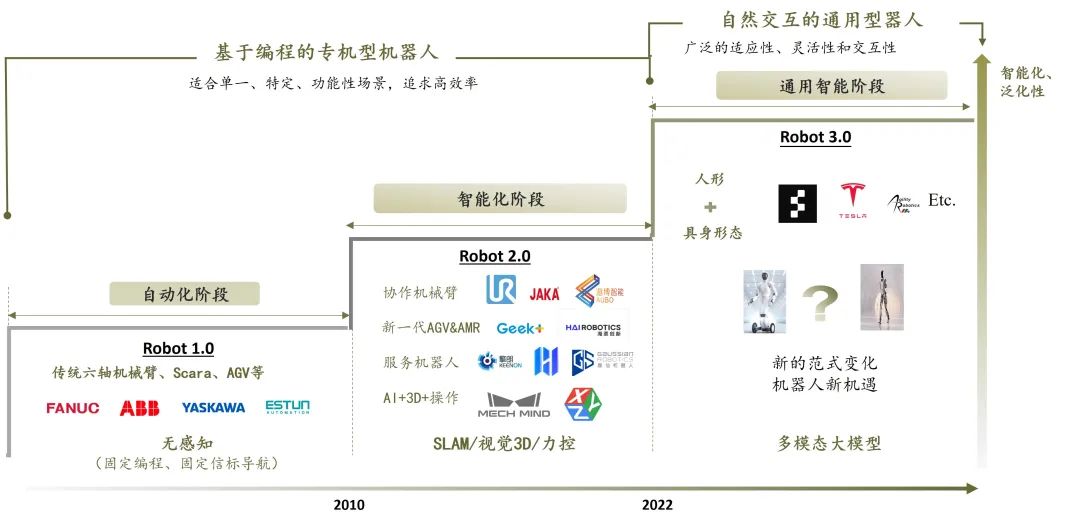
回顾机器人的发展阶段, 实质是从专机到逐渐通用,从被动编程控制到主动决策的过程。 在前两代机器人发展中,机器人更接近于专机型的自动化和智能化设备,以特定的机械结构解决针对性场景的作业问题,适用于相对单一、固定的结构化场景,泛化和迁移能力非常有限。此外机器人 各种能力的实现要依赖于工程师的精细编程, 由于机器人缺乏对任务目标的深入理解,机器人工程师需要进行大量的任务分解和编程工作,严重依赖手写代码来实现对机器人的控制,需要人工精确地规划每个步骤,且当任务对象或环境发生任意变化时,需要再次重新进行编程和部署,耗时费力。
Robot 1.0 时代
机器人主要承担自动化的目标,广泛应用于工业领域,比如执行精密、重复的组装和搬运工作。机器人形态主要为机械臂、小六轴、 SCARA 等 ,精确地按照预设的轨迹和速度执行;移动端则以传统的工业 AGV 为代表,通过固定的信标导航。这一阶段的机器人不具备感知和决策能力,依赖于预先编程的控制指令,在固定的产线执行任务。这一阶段四大家族机器人是主导力量并占据了核心市场,产业的新机会主要来自于国产替代的驱动和下游汽车等终端行业需求的推动,埃夫特、埃斯顿、新时代等国产机器人品牌跃上舞台,这一代机器人推进了整体行业自动化能力水平。
Robot 2.0 时代
机器人开始拥有了初步的感知和规划能力,开始向智能化衍进。在单点技术突破和新品类创新的驱动下催生了机器人 2.0 时代的几波创业潮和新机会:
• SLAM 技术驱动移动机器人新形态
随着 SLAM 空间感知定位技术的成熟,与机器人的结合赋予了机器人自主移动的能力,开辟出了多条新品类的赛道。石头科技率先将 SLAM 技术应用于家用扫地机,通过技术革新从传统的随机碰撞转变为智能路径规划清扫,直接颠覆扫地机器人的市场格局。工业移动机器人领域,传统移动机器人依赖于磁条或二维码等固定信标进行导航, SLAM 技术+激光雷达的结合为新一代具备自主移动能力的 AGV(自动引导车)和 AMR(自主移动机器人)打开了新的可能性,在电商仓储领域下游应用的需求推动下,涌现了几十家创业企业,诞生了极智嘉、快仓、海柔等公司。在服务机器人领域,基于 SLAM 技术的自主移动能力上构建了诸如配送、迎宾、送餐、清洁等移动服务机器人产品,如高仙、擎朗、普渡、云迹等各自打开了服务机器人的市场。
• 协作机械臂新品类
2012 年全球首家轻量级协作机械臂优傲(Universal Robots)进入中国市场,将协作机器人引入中国市场。协作机械臂因其轻量化、小型化的特点,以及相对较低的精度要求和简单的交互界面能在人机协作的场景中应用,成为机械臂领域的新兴产品类别。由于协作机械臂的发展起步较晚,与其他高精度工业机械臂相比差距较小,被认为是国产机器人弯道超车的机会。因此在 UR 进入国内不久,同时在工业 4.0 和智能制造 2025 的推动下,从 15 年左右开始掀起了协作机器人的创业热潮,遨博、节卡、越疆、珞石等诸多协作臂公司应势而生。
• AI+3D 视觉技术驱动
在机械臂领域,AI 和 3D 技术为机器人赋予了视觉感知和智能化能力,机械臂有了“眼睛”。通过 AI 与 3D 视觉技术的结合,机器人能够自动进行物体识别和定位,实现最优路径规划,从而减少了对人工示教和部署的依赖,并且手眼协调的柔性化能力拓展了工业机器人的应用范围,成功解决了上下料、拆码垛、无序分拣、焊接等非标准化自动化场景的难题,带来了新的机遇和市场空间。
Robot 3.0 通用智能阶段
大模型所展现的泛化能力,为通用智能机器人的实现带来了全新的可能性。不同于上个阶段的单点性驱动,我们认为此次 AI 与机器人的结合将对机器人感知 – 决策 – 控制的整体系统能力带来全面重构,在更大范围扩展机器人的能力边界,带来更广泛的市场新机会,对机器人行业影响也更为全面和深远,机器人进入全新的发展范式。
Part Ⅱ
解析机器人大模型
结合 AI 大模型与机器人的前沿研究已成为学术和产业界的重要热点,研究成果不断涌现(参见下图)。那么,机器人大模型将如何影响机器人的发展范式?

以机器人系统视角解析
机器人运行的核心系统组成包括:Perception(感知)、决策&规划(Decision Making and Planning)、动作控制和生成(Control&Act Generation)。在具身智能的体系中,可对应为 high level 的大脑决策和 low level 小脑控制执行两个系统,“大脑”负责理解任务,结合感知信息对任务进行分解以及规划,并做出执行策略。“小脑”则负责核心的运动控制,在大脑的策略下实现机器人动作的执行和反馈。

我们把与机器人结合的大模型分为两类: Foundation Models for Robotics 和 Robotics Foundation Models。 前者是可与机器人结合但并不限于机器人领域应用的各类 LLMs & VLMs & VFMs 多模态大模型,后者是结合机器人数据训练,可生成到小脑层控制的基础模型,即 机器人具身大模型。
多模态大模型与机器人大脑
对于第一类大模型——语言 LLMs & 视觉多模态大模型 VLMs,可作用于机器人大脑层,这类大模型可以为机器人提供强大的通识理解能力和强交互性,同时融汇了人类社会的知识和常识体系,能进行高层次任务抽象和理解规划,大幅提升了机器人大脑能力。
• 感知层面:大模型赋予多模态感知能力
传统的机器人感知系统往往依赖于单一的数据源或传感器,且受限于传统的 AI 能力,针对每一个不同的物品都需要进行大量的数据标注和监督学习,泛化性较弱。多模态大模型可以将不同传感器收集的多模态异构数据融合,比如对文本、图像、视频、音频等模态信息的学习和理解,实现更高的精确度;并且强大的泛化能力能够让机器人在感知中基于少量的新增数据微调就可以实现更通用的感知识别。代表如 Palm-E 模型,集成了参数量 540B 的 PaLM 和参数量 22B 的视觉 ViT模型,将大模型能力泛化至 CV 领域,为机器人提供了通用性的视觉感知能力。
可以预见,机器人感知系统在未来将集成更多的物理世界维度信息,如力控、触觉、嗅觉和物理定律等。多模态模型将更深入地发展为更多维的世界模型,从而赋予机器人比人类更为丰富和精准的多维感知能力。
• 规划层:大模型替代工程师实现高层规划
大模型之前应用工程师的主要工作就是理解任务,并把任务拆解成合适的动作,使用机器人编程语言完成机器人应用程序的编写、调优和部署。原来机器人的控制依赖于精准的建模,但建模也通常是针对某一特定的环境,当环境发生任一变化时,模型又需要重构,可迁移性有限。大模型对任务的高层次抽象能力,能使得原来工程师耗费大量时间进行机器人任务定义、拆解和编程的工作可直接由大模型接管,机器人真正实现自主任务规划。
多模态大模型可与机器人应用结合,增强机器人大脑能力,但仅通过提示现成的 LLMs/VLMs 来直接控制机器人具有挑战性,这一类模型并不适合直接做底层精确的控制,还需要小脑层的控制能力补充。因此大脑的决策规划与小脑的执行如何更好对齐,实现大模型到机器人的任务闭环非常关键,也是当前各研究团队在致力解决的问题。
具身大模型与机器人小脑
结合多模态大模型的能力可以为机器人的大脑层提供高层次的规划,但它们无法直接实现机器人的底层控制和动作生成,因此仅依赖于大脑模型不能完成机器执行的最终闭环。相对而言,小脑层作为控制和执行动作的底层控制系统,将高层决策转化为具体的动作执行,并负责最终的执行结果。Robotics Foundation Models 具身模型则是能延伸到小脑层控制,结合机器人的数据训练,实现机器人动作执行端的生成能力。代表如 Google RT 系列,利用 transformer 模型结合实际采集的机器人数据,实现从原始信息输入端比如图像、语音到机器人执行末端 action 的输出,并展示出了一定的泛化能力。
但受限于机器人的数据匮乏,当前具身模型数据参数量到构建真正的具身大模型还有较大差距。以操作为例,小脑控制的更好实现需要在底层构建一系列丰富的基元级动作库,如抓取、擦拭、折叠、放置等。不同于大脑层模型的训练可以脱离特定硬件形态,小脑层则需要进行算法与硬件端的强耦合训练,大量的动作数据。因此在小脑具身模型中,技能学习成为了具身智能实现的基石任务,技能集的成功率训练与泛化是关键问题,有些复杂的基本技能学习也是当前面临的主要难点。
• 机器人底层控制:从 Model-Based 向 Learning-Based
传统机器人通常采用经典控制策略,通过直接驱动或电机控制来实现基础动作控制。这种方法主要涉及动力学建模和约束器设计,并在底层采用 PID 控制器进行调节。AI 与控制的结合,模仿学习 (Imitation Learning) 和强化学习(Reinforcement Learning)等方式被越来越多采用,机器人的控制能力逐渐向自主化方向发展,更高级别的自适应和智能化控制。以足式机器人的控制发展历程为例,经历了大致三个阶段:
第一阶段:以 LIMP(Linear Inverted Pendulum Model)+ ZMP(Zero Moment Point)为主的基于规则的简化模型,这种方式简化位置控制但步态稳定性差。
第二阶段:引入动力学模型,MPC((Model Predictive Control))+ WBC(Whole Body Control),能进行动态的建模控制,支持更多的动作能力,但是算法对硬件的变化比较敏感,复杂及精准建模难度高。
第三阶段:近几年结合 AI 的控制算法,引入深度学习和强化学习等方式,AI 控制的环境适应性强,能突破传统控制方法的限制,提升机器人运动能力的上限。
基于模型的控制(Model-Based Control)具备更稳定性、可解释性和实时性优势,在简单控制任务中确保了机器人控制能力的下限。基于学习的控制(Learning-Based Control)通过数据驱动的方法,在解决复杂和高维度的运动控制问题上显示出潜力,但由于其黑盒学习特性,解释性、可靠性和安全性方面仍有待提升,但训练过程需要大量数据,和计算资源。 在足式控制领域,经典的模型控制与 AI 控制针对不同的任务场景融合应用;在具身操作与通用控制领域,目前的研究重点趋向于基于学习的控制策略,以实现更智能和泛化的机器人操作。
Part Ⅲ
具身智能的实现路径探究
端到端模型 vs 分层决策模型
在具身大模型的路径上,目前两种主流方式为端到端的具身模型(谷歌 RT-2 为代表)和分层决策模型( Figure 01 为代表)。
端到端模型是通过一个神经网络完成从任务目标输入到控制信号直接输出的全过程。这种方案以 Google RT-2 为代表,RT-2 的目标是训练一个学习机器人观测到动作的端到端模型,且能够利用大规模预训练 VLM 模型,直接生成 Low-level 的机器人运动指令的内容。RT-2 首先对 VLMs 在大规模互联网数据进行预训练,然后在机器人任务上微调,结合机器人动作数据,推出了视觉语言动作模型(VLA),能够从图像到控制指令的端到端输出,在 RT-2 模型中也展示了更好的泛化能力。端到端的方案能够通用、自动适应环境的各种变化,看上去是相对最直接最理想的实现方向。但在实际落地中缺要面临诸多难点:端到端要构建海量数据训练,以及消耗大量计算资源。且数据规模越大,加上调用大模型频率高,会大大降低机器人的决策速度,影响实时性。当然,如果掌握足够的算力资源和足够的数据,通过大规模数据和算力的加持,也真有可能带来令人惊艳的暴力美学效果。
分层决策模型方案,通过分解成不同层级的任务或者模块,以多个神经网络训练,再以 pipeline 的方式组合。 例如 Figure AI 公布的 Figure 01,最顶层链接了 OpenAI 的大模型(可能是GPT-4V),提供视觉推理和语言理解;中间层 Neural Network Policies(NNP),神经网络作为小脑进行 lowlevel 的控制,做出一系列快速、低级、灵巧的机器人动作,直接将像素信息映射为动作指令,并以极高的频率生成这些指令。Figure 01 的 policy network 能够以高达 200Hz 的控制频率输出动作指令,让人惊艳,端到端的方式不太可能做出如此快的响应效果。最底层为 Whole Body Control 接受 NNP 的动作指令,进行最底层的控制执行。这种分层架构可以相对可控,实现难度相对简单,底层还可以拆成不同的小模型,拥有很好的可解释性,在早期数据量不足的情况下,是更为合适的选择。但分布决策需要花更多时间去解决的是不同步骤间的对齐和一致性问题。
模仿学习与强化学习
具身智能小脑侧的训练方式主要集中在模仿学习和强化学习两大类。
• 模仿学习(Imitation Learning)
通过观察一个专家(人或另一个机器学习模型),倾向于从优秀的个体展现出来的技能中快速学习。这种学习方法本质是对示范的直接映射,因此所学习到的策略和行为通常受限于示范数据,无法超越这些数据所展示的能力边界。模仿学习的优点则是比较直接简单,能够快速地从专家的示范中获得知识和技能。
代表性如 Stanford Aloha,提供了一套用于模仿学习的完整的遥操作系统,可以非常快速的学习看似复杂和长序列的任务组合。但模仿学习的局限性在于以模仿对象的经验值和策略为上限,迁移泛化能力较弱,可能无法有效适应变化的环境或任务需求,还需要大量高质量的示范数据确保学习效果和模型的性能稳定性。
• 强化学习(Reinforcement Learning)
强化学习,通过设计奖励机制,让机器人在与环境的交互中,学习如何在特定任务里获得最大累积奖励。与传统的监督学习不同,强化学习不依赖于预先标记的数据,而是通过试错的方式从经验中学习最佳的行为策略。可以理解为相比模仿学霸,强化学习更倾向于直接成为学霸。
强化学习很适用于复杂环境下的决策问题,允许机器人进行自主探索,因此有较强的泛化能力,能够适应各种不同的环境和任务。但设计合适的奖励函数是影响强化学习效果的关键因素,某些长序列任务的奖励函数设置较为困难。另外强化学习的所需的样本量很大,如果用真机训练损坏成本会很高。当前,大多数强化学习研究都基于物理仿真器进行模拟训练,因此需要解决仿真到真实环境的迁移问题(Sim-to-Real Transfer),以实现更好的效果。
模仿学习与强化学习并非互斥的方法,可以根据具体场景和需求进行有效结合。例如,模仿学习可以作为强化学习的一种启动方式,通过模仿已有的专家策略,能够更快地开始执行任务,随后逐渐过渡到强化学习阶段,使得强化学习不需要从零开始探索环境。另外,对于结构简单、易于建模的任务,可通过仿真环境强化学习进行快速训练。而对于长时序任务或者超出仿真环境能力范围的复杂任务,模仿学习则可以作为一种更为直接和有效的学习方法。模仿学习和强化学习可以相互补充,充分发挥各自的优势,从而提高具身智能系统的训练效率和性能表现。
真实数据 vs 仿真数据
规模化数据是当前具身智能模型实现的基础,不同的训练方式下对于数据采集的路径也各有侧重。基于现实世界的数据采集和仿真环境的模拟数据构成了具身训练的两大类型。
• 真实世界数据
在真实的物理环境通过机器人本体采集,直接可用的高质量数据,数据效果最好也是成本最高的,需要耗费大人力和大量硬件投入,且真机训练的损坏性比较大,因此在真实环境中进行如此大规模的数据量搜集非常困难。像 Google 凭借自己的资金和科研实力,耗费 17 个月时间收集了 13 台机 器人的 13 万条机器人真实数据,为 RT-1 和 RT-2 的打下数据基础。
遥操作(Teleoperation):通过人操作机器直接采集机器数据,数据质量高,可直接使用。但问题是需要投入人力和硬件在真实世界里采集,成本相对较高。遥操作更好的实现是构建一套适应更多机器人本体、兼容多传感器、更低成本、更安全的遥操作系统。
真机学习是直接的、高质量但难以scale up的数据方法。因此衍生了间接的人类数据采集的方式。
动捕的数据采集 & 视频学习:这类方式不直接通过机器人设备采集,而是通过现实中更容易取得的人类行为数据学习。比如可通过可穿戴设备或者通过人类行为视频。好处是这类数据成本更低,视频学习可以基于大量互联网的免费数据,数据量大。但是核心要解决的是数据从人到机器人的映射问题,这类数据的处理难度高,且数据噪点高,数据有效性有限,这类Passive data 可以用于 task pre-training,如果映射解决的更好能很大程度缓解数据瓶颈问题;
此外苹果 Vision Pro 的推出也为设备端采集提供了新的思路,如果结合 Vison Pro 作为数据采集的入口,随着 Vision Pro 的渗透提升,可能成为一个更普遍的人类数据采集平台。
• 仿真数据
通过仿真模拟器 simulator 进行数据采集相比真实物理世界数据是另一条思路。仿真数据成本低,可以大规模获取,且24小时持续训练,足式等复杂控制问题借助仿真数据和强化学习在最近的训练效果上取得了突出的效果,我们看到的各类惊艳的足式机器人demo,几乎都是在仿真环境中训练出来。 在机器人强化训练中,常用的仿真器比如 Isaac Gym ,Isaac Sim,ManiSkill,MuJoCo 等
但仿真数据的质量往往依赖于仿真器的能力水平,仿真器中环境、感知、机器人硬件、和控制中的任一建模差异,都可能产生 sim-to-real gap,因此 reality gap 的核心问题需要持续攻克。另外针对如鞋带、衣物等软体物品的仿真还是一个待解决的疑难领域,可能限制仿真数据在涉及到软体物品操作的应用。长期来看更精确、高效的仿真模拟器的性能提升,对于机器人数据难题将是重大的突破。
无论是基于仿真模拟还是真实数据采集,无论是用强化学习还是模仿学习的路径,不同的数据采集和模型训练方式组成了具身智能训练的多元化的技能树。当前在训练的思路上,不同团队以各自的优势点出发,从仿真模拟器性能优化、改善遥操作软硬件系统、优化强化学习的奖励机制到创新的数据采集手段和方式等,在不同方向的探索中去构建更出色的泛化性模型。在过程中,如何对技能工具进行深度优化?如何基于对任务的理解选择匹配的训练路径?如何分配时间和资源在不同技能树中的投入?都将是影响具身模型训练效果的核心要素。
Part Ⅳ
挖掘具身智能的“六便士”

通用具身智能的三大核心要件
全球范围内围绕具身智能的新成果层出,为通用具身智能的实现带来了很大信心和期待。不过在仰望“月光”的同时,我们也看到当下的挑战。在通用具身智能的实现上有三个核心要素:机器人算法的 Scaling Law 、通用的机器人硬件平台和大规模的数据飞轮。
• 数据飞轮
用于训练机器人的高质量数据非常匮乏,仿真数据和真实数据都有各自当前面临的难题尚未突破,要达到大模型对于数据量的需求仍需长时间采集和积累,可以说数据端是实现具身大模型以及机器人通用化的最大的挑战同时也是核心的壁垒,构建一个高效、高质量、低成本数据训练 – 反馈机制则非常关键。
• Scaling Law
机器人的 Scaling law 在哪里?大脑端的感知规划借助多模态大模型已经有了很大的泛化提升,而涉及的机器人运动控制的具身模型的 Scaling law,是当前都在探索的问题。Scaling law 的实现同时需要更优的“菜谱”和足够的“原料” 。“菜谱”端而言,在前文分析中,提及了在具身智能实现上不同的训练路径和视角。随着具身研究的深入,算法模型在泛化性和通用性上可能有进一步突破,但实现速度上,还是会受限于数据集的体量,更有可能是分模块、分阶段逐步向 Scaling law 靠近。
• 通用硬件平台
硬件端是机器人执行的最终载体。如何定义通用的硬件平台,使之在可接受的成本约束下,能应对不同的任务要求、稳定可靠的执行任务、并助力数据的高效采集和反馈、同时保证充分的安全性?硬件的设计迭代和性能优化将是持续打磨的过程。
从机器人产业视角理解具身智能
具身智能本质仍在机器人的产业链路上,遵从机器人产业的发展规律。回看机器人的发展过往,与 AI 行业相比,机器人的产业链路则更为复杂和漫长,一方面算法与硬件强耦合,另一方面从前沿技术的突破 —— 产品 demo 的形成 —— PMF 阶段进入小规模量产 —— 到大规模的商业化应用的过程需要经历更长的落地周期 。 从一个令人欣喜的 demo 到真正产品量产商业化将会面临大量基于稳定性、鲁棒性的工程化问题,这需要我们有足够的耐心和韧劲。
机器人核心价值维度体现在三个方面:
• 扩展人类能力边界:执行危险、极端或者人难以完成的任务
• 机器替人:替代人类完成重复、单调或者高强度的劳动
• 提供精神交互与陪伴
在前两个价值维度里, 机器人均充当了新型生产力工具的角色,在应用决策中,仍要遵循人力成本和机器人替代成本 ROI 的回报测算逻辑。 因此,具身智能的产品无论带着怎样的技术光环,仍然需要面临机器人产业规模化过程中需求验证、成本管控、客户成功、硬件供应链管理、交付履约效率等方面的核心约束和挑战。敬畏产业发展链路,保持耐心和定力,在仰望月光的同时也夯实脚下的路。
具身智能领域正经历着快速的技术创新和突破,这些创新将大大拓展机器人在各种应用场景中的潜在价值和应用边界,带来全面的市场机会。但仅有技术突破,并不足以支持具身智能的产业化,具身智能的技术突破需结合好的功能或产品定义以及真实的场景需求才能真正实现商业闭环。在确定应用场景时,技术只是实现能力边界的一部分,而如何结合技术边界,结合场景定义好产品,需要仔细琢磨及判断真实的需求,深入挖掘在具身应用中的“六便士”。
本文来自微信公众号“緑洲资本 Vitalbridge”(ID:Vitalbridge),作者:参赞生命力

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则