- 行业先锋
- 文章详情

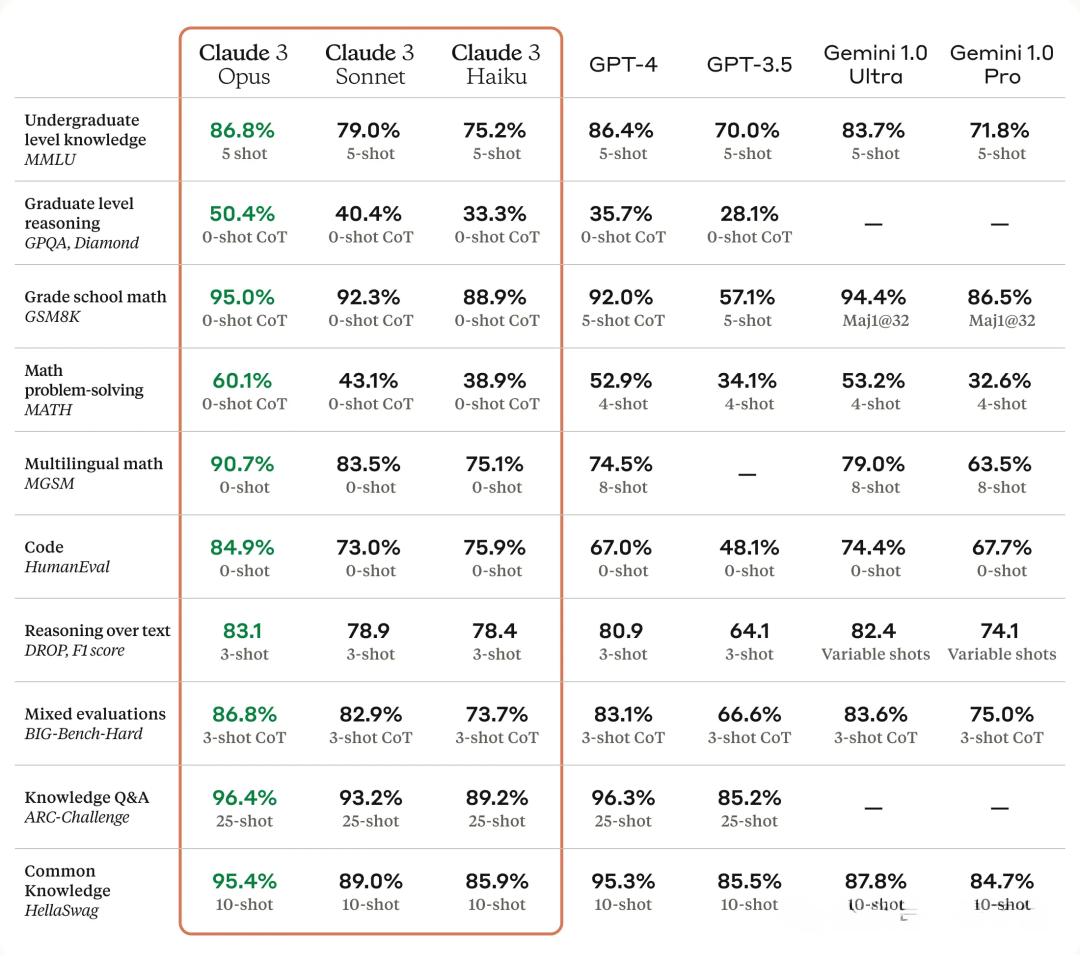
Claude3凭什么这么强?
春天到了,和万物一起竞发的,还有愈发火热的AI。
自2月以来,国外头部AI企业大招连出,纷纷推出了一系列强大的AI模型或技术。
除了在AI圈刷屏刷到爆的Sora以外,另一匹黑马Claude 3也在三月份杀出,直接夺取了GPT-4最强大模型的地位。
具体来说,在各种复杂任务的分析和推理方面,Claude3的表现最为炸裂,不仅在研究生级别的推理任务上全面超越了GPT-4,而且在进行物理、化学领域的高级课题研究时,表现出了与人类一样,甚至超越人类的水准。
Claude3的性能由高到低分为了Opus、Sonnet、Haiku三个级别,而最高级的Opus版本,可以在几分钟内,化身为经济学专家,根据各种数据预测美国GDP在下一个十年可能的范围。
Claude3通过观察浏览器界面上的趋势线来估算数字(多模态能力),并利用Python解释器编写代码生成图像。

在测试中,研究人员会给模型很多关于美国经济的数据(也就是有真实答案的数据),让它去预测,之后将模型的预测结果和历史上的真实结果做对比。
这并非仅基于先验知识,而是通过大量虚构GDP图表的测试得出的。
最终,模型的预测准确度在5%以内。

照这样来看,“AI计划经济”似乎指日可待了啊有没有!
除了预测经济走势外,Claude3在语言能力上,尤其是在翻译某些冷门语言方面,也展现出了强大的实力。
之前,一位名叫「An Qu」的网友表示,自己花了两年时间,在为自己的母语切尔克斯语研究NLP(自然语言处理)。这种语言极其小众,几乎没有任何互联网资源。据估计,在俄罗斯境内使用切尔克斯语的人口大约只有55万人。

而使用Claude 3 之后,Claude 3 不仅提供了完美的翻译,甚至还分解了语法和形态!
看到这种情况,网友们集体震惊了。


同样地,在科研方面,Claude 3 在某些方面也做到了博士级别的推理能力。
例如,一名叫Ben Blaiszik的化学博士,在使用Claude 3研究粘合剂材料(如氰基丙烯酸酯和环氧固化剂)的微胶囊化这个课题中,发现它只用了5分钟,就给出了详细技术方案!

后来,Ben Blaiszik发现,Claude 3对于实验细节的描述非常准确,完全符合实验室的标准和要求。而类似的方案,需要顶级化学家花费大约一年的时间,通过各种实验才能最终完成。
而做到这一切,Claude 3只花了5美分!
面对Claude 3这一系列炸裂的表现,不少国内AI圈的人惊呼:国内AI,又被美国甩开了。国产大模型危矣!中国AI危矣!
01 逆袭的可能
面对如此巨大的差距,国内对中国AI将来道路的看法,也出现了分歧,具体来说,中国科技界针对大模型的态度,已分裂成两股阵营。
一拨是技术派,这些人大多是技术出身,他们觉得得应该像美国的OpenAI那样,坚定地追求AGI,他们相信,只要模型够大,功能够多,成本够低,就能做出很多很牛的应用来(所谓的scaling law)。
他们担心,如果不继续追求更强大的AI,别的国家或者公司领先了,咱们就会被“降维打击”,甩得远远的。
另一拨是市场派,这些人更看重怎么快速赚钱。他们认为技术发展得再快,早晚也会慢下来,所以现在应该把现有的AI技术,用到能快速见到钱的商业场景里去。他们觉得中国的市场大,数据多,这些都是构筑行业壁垒的绝佳条件。
关于第二种观点,之前刷屏的《朱啸虎讲了一个中国现实主义AIGC故事》就是一个典型代表。
那篇文章大意是,朱啸虎觉得现在搞大模型的公司有点太烧钱了,而且商业模式也不太明确。老这么在技术上死磕,实在难以为继。
所以他建议创业者要实际一点,别光想着技术多牛,得多想想怎么赚钱。
在部分人(尤其是技术派)看来,朱啸虎的这一主张,颇有种“曲线救国”的味道。

因为正面拼技术拼不过了,特别是现阶段AI算力上确实有差距,所以只好退而求其次,用规模和市场招架OpenAI这类AI巨头的凌厉攻势,并寄希望于开源模型有一天会缩小,甚至拉平与闭源模型的差距。
那么,按照这样的观点,在中美AI差距越来越大的情况下,放弃“逆袭”的幻想,专心致志地在商业的土地里刨食,才是中国AI正经的出路吗?
从实际案例来看,话还真不能说那么死。
因为在AI方向上,有时候搞出“震撼”动静的,并不总是手握大量算力和资金的科技巨头,而更有可能是某些短小精悍的技术派团队。
当初羽翼未丰的OpenAI,靠GPT逆袭财大气粗的谷歌,正是这样一个例证。
而现在,类似的剧本也发生在了Anthropic与OpenAI之间。
从资金和规模上来看,Anthropic目前估值为150亿美元,拥有员工大约300名。而OpenAI则已然是个估值超过900亿美元的科技巨头,麾下聚集了1000多名业内最顶尖的AI人才。
但就是在这样的实力对比下,Anthropic的Claude 3却将GPT-4硬生生超越了。
那他们到底是怎么做到的?
02 可解释性的重要
用一句话来总结,Claude 3之所以能战胜GPT-4,靠的或许并不是比前者更强大的算力,而是在可解释性方面的突破。
就目前来说,虽然大模型的训练、研发,确实非常耗算力,非常烧钱,但要想整一个性能强大的大模型,单纯靠堆参数的办法“大力出奇迹”,却未必总能奏效。
原因就在于,与其他科学领域相比,AI大模型的研究,还没有产生像物理学中的牛顿运动定律或化学中的元素周期表那样确定的第一性原理。
换句话说,没有收敛出一个统一的理论框架。
(注: 在深度学习中,“收敛” 指的是训练过程中模型逐渐学习并改善其性能,直到达到一种稳定状态。)
在这种情况下,用的劲儿再大,没用对地方也是白搭。
而这第一性原理之所以那么难确定,最主要的原因,就是“黑盒问题”的存在。
所谓黑盒问题,简单来说,就是“大家不知道大模型里面发生了啥”。
在AI大模型中,这个黑盒子就是一个复杂的神经网络,你给它一些数据,它就会做出相应的输出。但是,这个过程就像一个黑洞洞的盒子,你不知道AI在其中是怎么得出答案的,为什么会产生这样的输出。

在黑盒问题没解决的情况下,一味地增大模型参数,会产生什么后果?
这方面,OpenAI已经成了第一个“撞到南墙”的人了。
具体表现,当某些模型变得更大时,它们的错误率会下降,然后上升,然后再次下降。走出了一个形同抽风的W形曲线。
这就使得GPT-4这样的大模型有时很难学会某一技能,过后又能突然学会。
再者,这类黑盒问题,还会导致令人诟病的模型“变懒”现象。
自去年11月起,很多用户就发现,GPT-4不但回答的时候更敷衍,还缺乏创造力,更不愿意遵循指令,也不太能保持角色扮演了。
这样的问题,在代码任务方面尤其严重。
比如要求用别的语言改写代码,结果GPT-4只改了个开头,主体内容用注释省略。

后来,有研究者发现,这可能是由于所谓的“任务污染”现象造成的。也就是说,GPT-4在处理新任务时,更多地依赖于记忆训练数据中的信息,而不是真正理解任务。
这实质上也是“黑盒问题”的一种体现。
由于模型的内部工作机制,对于外部观察者(研究人员和用户)来说是不透明的,我们很难知道模型在给出答案时,究竟依据的是什么。
只要这种“黑盒问题”不得到解决,模型参数越大,遇到的错误和BUG只会越来越多,模型的行为机制也会变得越不可控。
这样的模型,即使性能再强大,也很难广泛地投入各个行业使用,尤其是在医疗、法律和金融之类对准确性要求较高的领域。
比如在医疗领域,你想象一下,病人来看病,大模型一通乱诊:
“您的症状符合恶性肿瘤,需要立即开刀切除…不对不对,我重新算算,您只是感冒发烧而已,来几片布洛芬就行了。嗯?还是不对,因为您得的是重度肺炎…”
这样的诊断,病人怕是没病也要吓死。
这也许就是为什么,OpenAI直到现在还没能推出GPT-5的原因,因为单凭堆算力、堆参数根本就解决不了这个“黑盒难题。”
而对“黑盒问题”的攻克,本质上就是一种增强可解释性的工作,而这正是Claude 3背后的团队Anthropic所擅长的。
03 让模型可控
Anthropic为何这么擅长可解释性的钻研?
这还得从他们创始人的背景说起,Anthropic的创始人Dario Amodei,这哥们就是属于那种特别学术派,又特别爱钻牛角尖的技术天才。
早在谷歌做量子AI研究时,他就开始痴迷于探索AI模型内在运作逻辑的事了。

后来,在OpenAI工作期间,主要的工作职责是提高大模型的安全性和可靠性。而这正是和增强模型的可解释性高度相关的工作。
在此期间,他钻研出了”重编码”(recoding)、因果建模(causal modeling)等前沿理论,用于分析大模型内部的工作机制和推理过程。
那就当下来说,Anthropic是怎么增强Claude 3的可解释性的?
鉴于Anthropic目前并没有公开具体的核心技术(这本来也不太可能……),所以,我们在查阅了之前Dario Amodei发布的大量论文,以及相关的访谈之后,从他的理论方法中,大致总结出了其中两种可能的技术路径。
其一是通过“玩具模型”的办法,摸清模型的机理。
具体技术思路是:先弄一个简单的AI模型,然后用另一个AI模型去模仿这个简单模型的工作原理。通过这种方式,研究者能够构建一组特征,并预测这些特征如何映射到真实AI中的神经元。

这就像是,一个人车技不稳定的人(大模型)在现实中开车,遇到的变量会很多,人们对他不放心,所以先弄了个模拟驾驶的游戏(玩具模型),让这个人先玩玩,并从他玩游戏时的思路和习惯,推导出他在现实中开车时,哪些因素会影响他的发挥。
在大模型的研究中,这种“玩具模型”就是现实世界复杂系统的简化版。
而使用这种“玩具模型”的好处,就在于研究人员可以在受控的精确条件下,搞清楚为什么大模型中的神经元,有时可能会代表多个不相关的概念(学术上称为“叠加”现象)——这个问题可太重要了,它是大模型“可控性”的关键。
举例来说,神经网络中有一个神经元专门负责识别“猫”这个词。但是,由于叠加现象,这个神经元可能不仅仅对应于“猫”这个词,它也可能对应于其他与猫相关的词汇,比如“宠物”、“毛茸茸的”或者“捕鼠”。

这样一来,聊天的准确性和相关性就会受到影响。
这就像你有一个开关,你希望它对应明确的功能,可按下去的时候,它一会儿启动的是冰箱,一会儿启动的又是空调,这着实让人很蛋疼。
那么,通过上面提到的“玩具模型”的办法,Anthropic找到对付这种“叠加”问题的策略了吗?
这就要提到第二种关键的技术路径:稀疏自动编码器。
04 大模型的“牛顿定律”
在解释稀疏自动编码器之前,可以明确的告诉大家,在去年10月份的时候,Anthropic就已经打破了大模型黑盒,彻底分解了神经元对应的特征。
这种对大模型可解释性的攻克,影响不亚于物理学中牛顿三大定律的发现,或是化学中元素周期表的出现。

这可以说是人类揭开AI“黑盒难题”的里程碑式的一步。
而Anthropic团队之所以能做到这点,靠的正是稀疏自动编码器技术。
前面提到,为解决大模型中的神经元中的“叠加”问题,Anthropic采用了一种“玩具模型”的办法,在具体观察中,Anthropic发现了三种有效的策略,分别是:
1、创建没有叠加的模型:这就像是尝试制造一个新机器,里面的齿轮(神经元)每个都只负责一个特定的任务,这样就不会有重叠的功能,更容易理解每个齿轮的作用。
但是,即使每个神经元倾向于处理一个主要功能,复杂任务中上下文的变化,仍可能导致它参与表示多个概念,从而无法完全消除多义性。
2、使用字典学习:这就像是我们有一本字典,可以告诉我们每个齿轮(神经元)通常参与哪些任务。这样我们可以更好地理解它们的作用。
但这种方法,可能会导致我们过于依赖这本字典(分类方法),而忽略了神经元在实际工作中可能发生的复杂交互和多重角色。
3、混合方法:这就是结合前面两种方法的优点,试图找到一种平衡。
Anthropic的研究人员选择了第三种方法,并使用了一种特殊的技术(稀疏自动编码器)来帮助他们理解这些复杂的齿轮(神经元)。
具体来说,稀疏自动编码器,就像你电脑上的WinRAR或者ZIP一样。它的作用是把一大堆复杂的信息压缩成简单的形式,但是压缩的时候,它尽量只保留最重要的信息,忽略那些不重要的细节。
之后,稀疏自动编码器会对这些信息进行分析,找出那些对模型决策影响最大的特征。然后,它会把这些特征组合起来,形成一个更加简单、更加容易理解的表示。

如上图所示,这些小点代表了自动编码器在分析过程中,找到的各个特征或模式。
在具体操作中,Anthropic研究人员用了一个只有512个神经元的简单模型,之后从这个模型的输出的80亿个数据点中,找出了数量高达131,072个的重要特征。 在这一万多个特征中,可解释的特征一共有4000多个,包括了法律语言、DNA序列等。
通过这样的办法,人类算是第一次将大模型内部的机理解剖出了个头绪。
开头提到过,Claude 3目前已经在经济学,语言学,物理和化学等多个领域表现出了接近甚至超过人类的水准,而这种强大的推理和分析能力,实际上是在经过大量数据学习后,涌现出的一种高级智能。
然而,由于“黑盒问题”的存在,这种涌现出的能力,往往具有一定的不可预测性,有时会表现为偶然的“惊喜”。而提高可解释性,正是为了让这样的“惊喜”变成一种可复现的,能够逐渐改进和增强的能力。
05 对中国AI的启示
如果说,Claude 3对GPT-4的逆袭,对中国AI真的有什么启示的话,那这样的启示或许就是:在实现更强AI的道路上,Scaling law(规模定律)固然会发生作用,但要想让大规模的参数化作更高层次的“智能”,找对技术路径,远比一味地堆参数、堆算力要重要得多。
关于这点,国内的部分AI创业者也早已有了先见之明。
例如月之暗面的创始人兼CEO杨植麟,就是这独具慧眼的佼佼者之一。

作为一个毕业于清华计算机系,在卡内基梅隆大学受过深造,且与杨立昆(AI三教父之一)合著过论文的创业者,杨植麟对当下AI的技术路径,有着清醒而独立的认识。
尽管与很多人一样,杨植麟也是Scaling law的信徒,并且其研发的大模型Kimi.chat也是以长文本能力著称(20万字上下文窗口),但其并没有对“堆量”这件事表现出迷信。
之前,在接受腾讯科技采访时,针对现在很多大模型一味追求更长上下文窗口的现象,他就表示:“不能只提升窗口,不能只看数字,今天是几百万还是多少亿的窗口没有意义。你要看它在这个窗口下能实现的推理能力、the faithfulness的能力(对原始信息的忠实度)、the instruction following的能力(遵循指令的能力)。”
这也是为什么,面对今天各种动辄号称能处理128k,甚至200k长文本的大模型,Kimi.chat仍能脱颖而出的原因。
23年11月-24年2月,Kimi Chat访问量的月增速均超85%,2月访问量高达305万,较上月上涨107.6%;在国内AI产品访问量排行榜中的排名,更是直接从32位上升至第3位,仅次于百度的文心一言和阿里的通义千问。
而杨植麟和月之暗面的成功,着实与Anthropic及其创始人Dario Amodei有着某种相似之处:两人都是十足的学院派,且对AI技术都有着自己一套非常独立而执着的见解,不会轻易被市场、舆论所左右。

Dario Amodei此前很少接受媒体采访,声称这是为了避免外界的干扰
而这种技术专家掌舵,并且对自身技术路径“咬定青山不放松”的笃定,正是一个能在特定方向上做出重大突破的企业必备的基因。
从这点上来说,将来中国能够在AI方面实现“逆袭”的企业,或许并不是百度、阿里这样的大厂,而更有可能是月之暗面、智谱AI这样在学术上比较专精的小团队。
06 总结
月之暗面的成功,或许说明了,中国的AI企业要想和OpenAI等巨头继续掰手腕,最有效的策略,就是“攻其一点,不及其余”。
毕竟,真正意义上的AGI,涵盖的领域和方向极其广阔,单独一个企业很难在所有方向上都做到独占鳌头。
最近,OpenAI在多模态方面推出了Sora,却在最核心的文本能力上却被Claude 3反超,这本身就是一种顾此失彼的表现。
而在更多元化的维度上,OpenAI的霸主地位也在一点点被“肢解”。
例如在情商方面,Inflection-2.5就表现得比GPT-4更有人性;而在文生图方面,Stable Diffusion 3和Midjourney V6也早已对OpenAI的Dall-E3形成了问鼎之势;

在AI语音方面,Meta开源的「AI同传」技术更是独步全球,OpenAI至今也未能推出类似的竞品。
在此情况下,中国的AI企业,倘若能保持清醒而独立的判断,不去一味地比拼算力、数据,追求大而全的“通用模型”,而是潜心钻研某一特定的技术方向,只要在1—2个领域取得了前人未有的突破,中国的AI就能在世界上占有一席之地。
诚如杨植麟所说:如果你的理想是大家都能想到的,它对人类的理想总量没有增量。
这句话用在AI方面,也可以说成:只有当一个大模型,是世界上从未存在过的,它才会对人类通往AGI的道路起到推进作用。
本文来自微信公众号“酷玩实验室”,作者:酷玩实验室

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则