- 行业先锋
- 文章详情

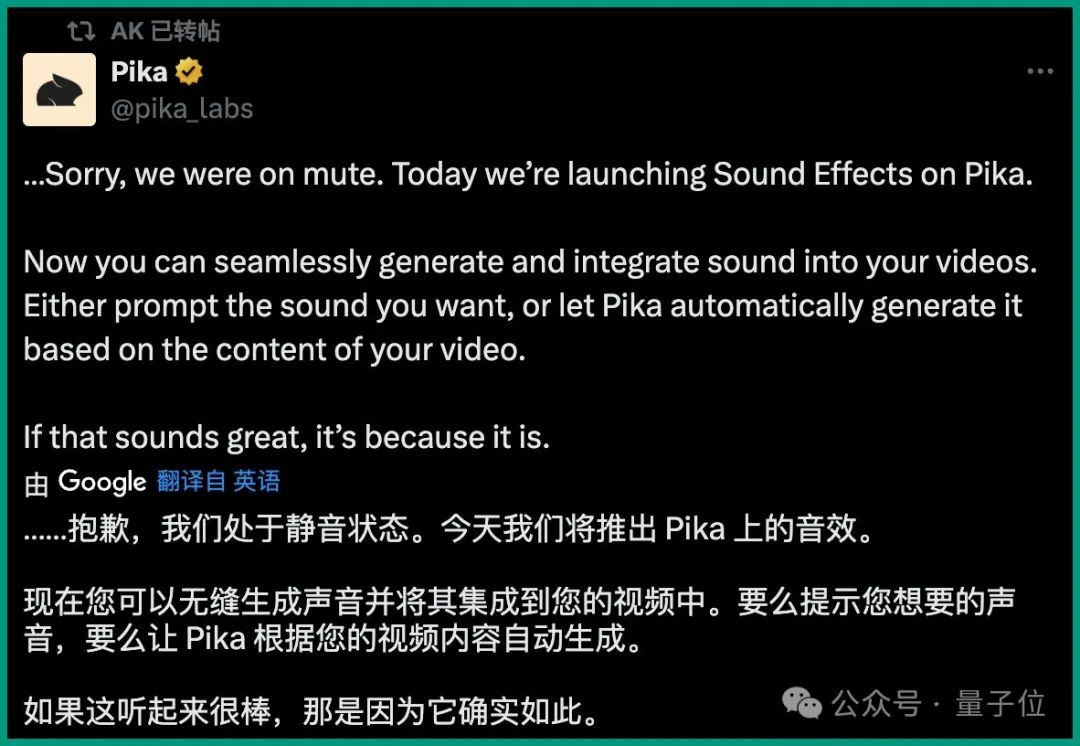
就在刚刚,Pika发布了一项新功能:
很抱歉我们之前一直处于静音状态。
今天起,大家可以给视频无缝生成音效了——Sound Effects!
生成的方式有两种:
- 要么给一句Prompt,描述你想要的声音;
- 要么直接让Pika根据视频内容自动生成。
并且Pika非常自信地说到:“如果你觉得音效听起来很棒,那是因为它确实如此”。
话不多说,我们直接来听一下。

车鸣声、广播声、鹰叫声、刀剑声、欢呼声……可谓是声声不息,并且从效果上来看,也是高度与视频画面匹配。
不仅是发布的宣传片,Pika官网现在也放出了多个demo。
例如无需任何prompt,AI只是看了眼烤培根的视频,便可以配出毫无违和感的音效:

再如给一句prompt:
Super saturated color, fireworks over a field at sunset.
超饱和色彩,日落时田野上的烟火。
Pika便可以在生成视频的同时配上声音,从效果中不难看出,烟花绽放的瞬间,声音卡点也是相当的精准:

大周末的发布这样一个新功能,网友们在高呼Pika“够卷、够Awesome”的同时,也有人认为:
它正在为多模态AI创作收集所有的“无限宝石”。

那么Pika的Sound Effects具体要如何操作,我们继续往下看。
给视频“make some noise”
Pika给视频生成音效的操作也是极!其!简!单!
例如只需一句prompt,视频和音效就能“一锅出”:
Mdieval trumpet player.
中世纪小号手。

相比于此前生成视频的操作,现在只需开启下方“Sound effects”按钮即可。
让我们听一下生成效果:

第二种操作方式,就是在生成了视频过后,可以单独给它配音。
例如在下面这个视频,点击下方的“Edit”,再选择“Sound Effects”:

然后可以描述一下自己想要的声音,例如:
Race car revving its engine.
赛车正在发动引擎。
然后短短几秒后,Pika就可以根据描述和视频生成音效,而且还是6种声音可选的那种!

值得一提的是,Sound Effects功能目前只对超级合作者(Super Collaborator)和Pro用户开放测试。
不过Pika也表示:“我们很快就会向所有用户推出该功能!”

然后现在已经有一批网友在开始测试这个Beta版本了,并且表示:
音效听起来和视频很相配,而且增加了很多气氛。

再如“壁炉里火焰的声音”,是这样的:

这位网友还用了额外的工具,在Pika生成效果的基础上,还让视频里的人物开口说话:

想要尝鲜Pika新功能的小伙伴,可以蹲一波Sound Effects的全面开放了。
什么原理?
至于Sound Effects背后的原理,虽然Pika此次并没有公开,但在此前Sora大火之后,语音初创公司ElevenLabs就出过类似的配音功能。
当时,英伟达高级科学家Jim Fan就对此做过较为深入的分析。
他认为,AI学习准确的视频到音频映射还需要对潜在空间中的一些“隐式”物理进行建模。

他详细说明了端到端Transformer在模拟声波时需要解决的问题:
- 识别每个物体的类别、材料和空间位置。
- 识别物体间的高阶互动:例如,是木棍、金属或是鼓面?以什么速度击打?
- 识别环境:是餐厅、空间站、还是黄石公园?
- 从模型的内部记忆中检索物体和环境的典型声音模式。
- 使用“软性”的、通过学习得到的物理规则来组合和调整声音模式的参数,甚至即时创造全新的声音。这有点像游戏引擎中的“程序化音频”。
- 如果场景很复杂,模型需要根据物体的空间位置叠加多个声音轨道。
所有这些都不是显式的模块,而是通过大量的(视频,音频)对的梯度下降学习来实现的,这些视频和音频对在大多数互联网视频中自然地时间对齐。注意力层将在它们的权重中实现这些算法,以满足扩散目标。
除此之外,Jim Fan当时表示英伟达的相关工作并没有这样高质量的AI音频引擎,不过他推荐了一篇MIT五年前的论文The Sound of Pixels:

感兴趣的小伙伴可以戳文末链接详细了解一下。
One More Thing
在多模态这件事上,LeCun在最新访谈中的观点也很火爆,他认为:
语言(文本)是低宽带的:小于12字节/秒。现代LLM通常使用1×10^13个双字节标记(即 2×10^13 字节)进行训练。一个人阅读大约需要 100000 年(每天 12 小时)。
视觉的带宽要高得多:约20MB/s。两条视神经中的每一条都有 100 万根神经纤维,每根神经纤维每秒携带约10个字节。一个4岁的孩子在清醒状态下大约是16000小时,换算成字节大约是1×10^15。
视觉感知的数据带宽大约是文本语言数据带宽的1600万倍。
一个4岁孩子看到的数据,是互联网上公开的所有文本训练的最大LLM数据的50倍。

因此,LeCun总结到:
如果不让机器从高带宽的感官输入(如视觉)中学习,我们绝对不可能达到人类水平的人工智能。
那么,你赞成这种观点吗?
参考链接:
[1]https://twitter.com/pika_labs/status/1766554610188095642
[2]https://www.youtube.com/watch?v=WirmtLi47q4
[3]https://pika.art/home
[4]https://www.youtube.com/watch?v=5t1vTLU7s40
[5]https://twitter.com/DrJimFan/status/1759287778268025177
[6]http://sound-of-pixels.csail.mit.edu/
文章来自于微信公众号“量子位”(ID: QbitAI),作者 “金磊”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则