- 行业先锋
- 文章详情

随着终端侧 AI 变革席卷全球,「小而强」的端侧大模型,成为行业主流玩家的必争之地。
面壁 MiniCPM,这颗超级能打的「小钢炮」,凭借独特的上千次「模型沙盒」实验技术路径,超越全球一众轻量高性能的标杆之作,成为小尺寸极限竞技场中的大模型王者:
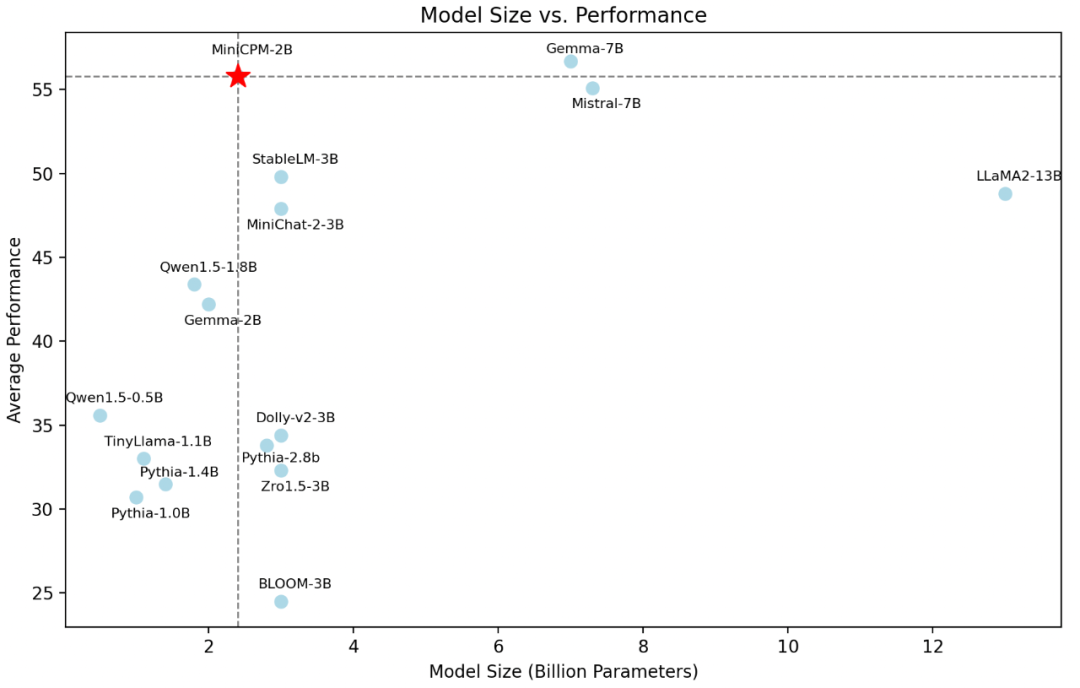
- 以 2B 规模、1T tokens,和来自「欧洲版 OpenAI」的 Mistral-7B 一较高下(图1);
- 相较晚一个月发布、来自谷歌的新星 Gemma 模型,2B 量级整体领先,7B 量级多项超越(图2);
- 在刚刚放榜的 SuperCLUE 评测中,以「以小博大」亮眼表现,超越智谱的 ChatGLM3-6B, Meta 的 Llama2-13B-Chat, 谷歌的 Gemma-7b-it 等更大规模明星模型(图3)。
此外,还将高效率与低成本发挥至极致——支持 CPU 推理,170 万 tokens 推理成本仅 1 元。目前,已支持 MLC-LLM, LLMFarm,FastLLM 等全球主流推理框架部署。
图1:模型性能同体量最强,越级比肩 Mistral-7B, Gemma-7B, Llama2-13B
图中模型评测均采用 UltraEval评测框架。选择常用的评测任务:C-Eval,CMMLU,BBH,MMLU,HumanEval,MBPP,GSM8K,MATH,HellaSwag,BoolQ,PIQA,WinoGrande,ARC-e,ARC-c,从不同的能力维度检验模型的能力,最终取所有任务的均值作为最终结果进行展示。

图2:面壁 MiniCPM 相较谷歌 Gemma
– 2B量级整体领先,英文均分领先(MiniCPM-2B 56.6 VS Gemma-2B 46.4)
– 7B 量级多项超越,中文均分领先(MiniCPM-2B 51.1 VS Gemma-7B 43.6), 标志性指标领先(HumanEval, GSM8K, ARC-c/e)

图3:SuperCLUE 2月榜单,取得 7B及以下量级领先优势
SuperCLUE是由创立于2019年的CLUE学术社区最新发布的中文通用大模型综合性评测基准。为更好地反映国内大模型与国际领先大模型间的差距和优势,SuperCLUE选取了多个国内外有代表性的可用模型进行评测,同时由于其数据集保密性高,减少了模型训练数据混入评测数据的可能性。
MiniCPM 受到全球开源社区广泛欢迎
MiniCPM一经发布,即问鼎 Github Trending Top1 与 HuggingFace Trending Top3,不到 1 月即在 Github 上斩获 3000 星标,模型下载量高达 27 万。
在社区引发热烈讨论,吸引了一众优秀开发者实践:

同时受到众多科技媒体赞誉(左滑查看更多):

文章来自于微信公众号 “OpenBMB开源社区”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则