- 行业先锋
- 文章详情

人工智能的反馈(AIF)要代替 RLHF 了?
大模型领域中,微调是改进模型性能的重要一步。随着开源大模型逐渐变多,人们总结出了很多种微调方式,其中一些取得了很好的效果。
最近,来自 Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,给人带来了一点新的震撼。
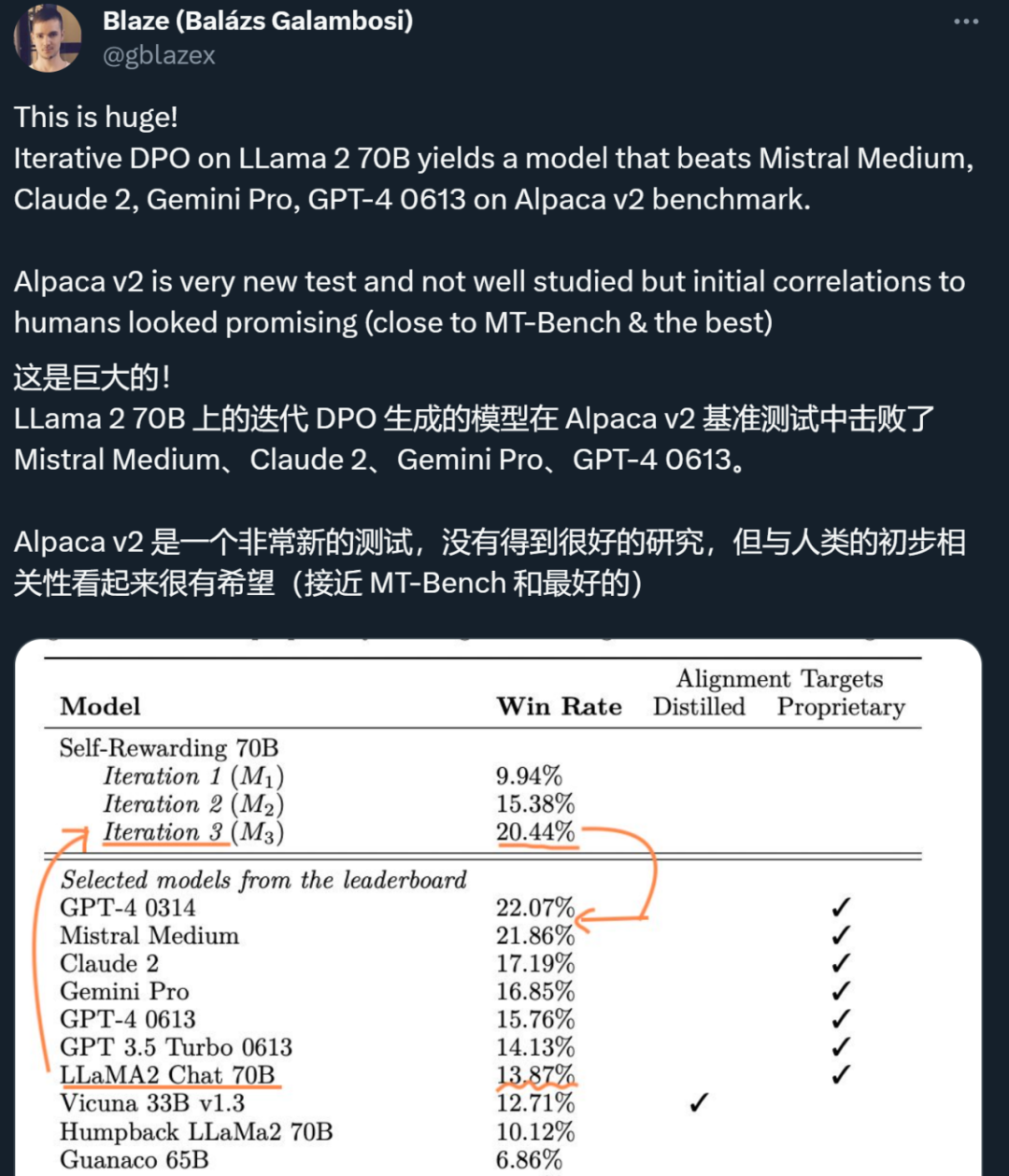
在新方法中,作者对 Llama 2 70B 进行了三个迭代的微调,生成的模型在 AlpacaEval 2.0 排行榜上优于一众现有重要大模型,包括 Claude 2、Gemini Pro 和 GPT-4。
因此,论文刚刚发上 arXiv 几个小时就引起了人们的注意。
虽然目前方法还没有开源,但是人们认为论文中使用的方法描述清晰,复现起来应该不难。

众所周知,使用人类偏好数据调整大语言模型(LLM)可以极大提高预训练模型的指令跟踪性能。在 GPT 系列中,OpenAI 提出了人类反馈强化学习 (RLHF) 的标准方法,让大模型可以从人类偏好中学习奖励模型,再使得奖励模型被冻结并用于使用强化学习训练 LLM,这种方法已获得了巨大的成功。
最近出现的新思路是完全避免训练奖励模型,并直接使用人类偏好来训练 LLM,如直接偏好优化(DPO)。在以上两种情况下,调优都受到人类偏好数据的大小和质量的瓶颈,并且在 RLHF 的情况下,调优质量还受到从它们训练的冻结奖励模型的质量的瓶颈。
在 Meta 的新工作中,作者提议训练一个自我改进的奖励模型,该模型不是被冻结,而是在 LLM 调整期间不断更新,以避免这一瓶颈。
这种方法的关键是开发一个拥有训练期间所需的所有能力的智能体(而不是分为奖励模型和语言模型),让指令跟随任务的预训练和多任务训练允许通过同时训练多个任务来实现任务迁移。
因此作者引入了自我奖励语言模型,其智能体既充当遵循模型的指令,为给定的提示生成响应,也可以根据示例生成和评估新指令,以添加到他们自己的训练集中。
新方法使用类似于迭代 DPO 的框架来训练这些模型。从种子模型开始,如图 1 所示,在每次迭代中都有一个自指令创建过程,其中模型为新创建的提示生成候选响应,然后由同一模型分配奖励。后者是通过 LLM-as-a-Judge 的提示来实现的,这也可以看作是指令跟随任务。根据生成的数据构建偏好数据集,并通过 DPO 训练模型的下一次迭代。

- 论文标题:Self-Rewarding Language Models
- 论文链接:https://arxiv.org/abs/2401.10020
自我奖励的语言模型
作者提出的方法首先假设:可以访问基本的预训练语言模型和少量人工注释的种子数据,然后建立一个模型,旨在同时拥有两种技能:
1. 指令遵循:给出描述用户请求的提示,能够生成高质量、有帮助(且无害)的响应。
2. 自指令创建:能够按照示例生成和评估新指令以添加到自己的训练集中。
使用这些技能是为了使模型能够执行自对准,即它们是用于使用人工智能反馈(AIF)迭代训练自身的组件。
自指令的创建包括生成候选响应,然后让模型本身判断其质量,即它充当自己的奖励模型,从而取代对外部模型的需求。这是通过 LLM-as-a-Judge 机制实现的 [Zheng et al.,
2023b],即通过将响应评估制定为指令跟随任务。这个自行创建的 AIF 偏好数据被用作训练集。
所以在微调过程中,相同的模型被用于两个角色:作为「学习者」和作为「法官」。基于新出现的法官角色,模型可以通过上下文微调来进一步提升性能。
整体的自对齐过程是一个迭代过程,通过以下步骤来进行:构建一系列模型,每个模型都比上一个模型有所改进。在这其中重要的是,由于模型既可以提高其生成能力,又可以通过相同的生成机制作为自己的奖励模型,这意味着奖励模型本身可以通过这些迭代来改进,这就与奖励模型固有的标准做法出现了不同。
研究者认为,此种方式可以提高这些学习模型未来自我改进的潜力上限,消除限制性瓶颈。
图 1 展示了该方法的概述。


实验
在实验中,研究者使用了 Llama 2 70B 作为基础预训练模型。他们发现,与基线种子模型相比,自奖励 LLM 对齐不仅提高了指令跟随表现,奖励建模能力也得到了提高。
这意味着在迭代训练中,模型能够在给定的迭代中为自己提供比上一次迭代质量更好的偏好数据集。虽然这种影响在现实世界中会趋于饱和,但提供了一种有趣的可能:这样得到的奖励模型(以及 LLM)要优于仅从人类撰写的原始种子数据里训练的模型。
在指令跟随能力方面,实验结果如图 3 所示:

研究者在 AlpacaEval 2 排行榜上评估了自奖励模型,结果如表 1 所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代 1 的 9.94%,到迭代 2 的 15.38%,再到迭代 3 的 20.44%。同时,迭代 3 模型优于许多现有模型,包括 Claude 2、Gemini Pro 和 GPT4 0613。

奖励建模评估结果如表 2,结论包括:
- EFT 增强比 SFT 基线有所改进。使用 IFT+EFT 与单独使用 IFT 相比,所有五个测量指标都有所改进,例如,与人类的成对准确率一致性从 65.1% 提高到 78.7%。
- 通过自我训练提高奖励建模能力。进行一轮自我奖励训练后,模型为下一次迭代提供自我奖励的能力得到了提高,此外它的指令跟随能力也得到了提高。
- LLMas-a-Judge 提示的重要性。研究者使用了各种提示格式发现,LLMas-a-Judge 提示在使用 SFT 基线时成对准确率更高。
作者认为,自我奖励的训练方式既提高了模型的指令跟踪能力,也提高了模型在迭代中的奖励建模能力。
虽然这只是一项初步研究,但看来已是一个令人兴奋的研究方向,此种模型能够更好地在未来的迭代中分配奖励,以改善指令遵循,实现一种良性循环。
这种方法也为更复杂的判断方法开辟了一定的可能性。例如,大模型可以通过搜索数据库来验证其答案的准确性,从而获得更准确和可靠的输出。
参考内容:https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_language_models_meta_2024/
文章来自于微信公众号 “机器之心”,作者 “机器之心”
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则